Go or No Go: Differential Fuzzing of Native and C Libraries
25 May 2023Overview
In 1892 an anonymous artist in Germany drew the now famous duck/rabbit optical illusion. It was soon popularized by psychologists and even Ludwig Wittgenstein. To one person it will be a duck and others a rabbit. What people see first is tied to their expectations and other mental models. This situation is not limited to humans, computers have similar difficulties in parsing input. Parsers in programming languages similarly can read the same input but draw different conclusions about what to make of the data.

Go
Go is a widely popular language for backend programming and powers large chunks of the internet. Go comes with fresh implementations of many parsers, yet allows to import code written in C which is often used to include older parsers to Go programs. When it comes to picking a parser, developers make a choice picking one over the other. This choice is not well understood, as these parsers can disagree on certain inputs leading to diverting behavior. We were wondering whether these divergences can be leveraged for security and correctness testing, and developed a differential fuzzer to study such effects and identify vulnerabilities.
Fuzzing
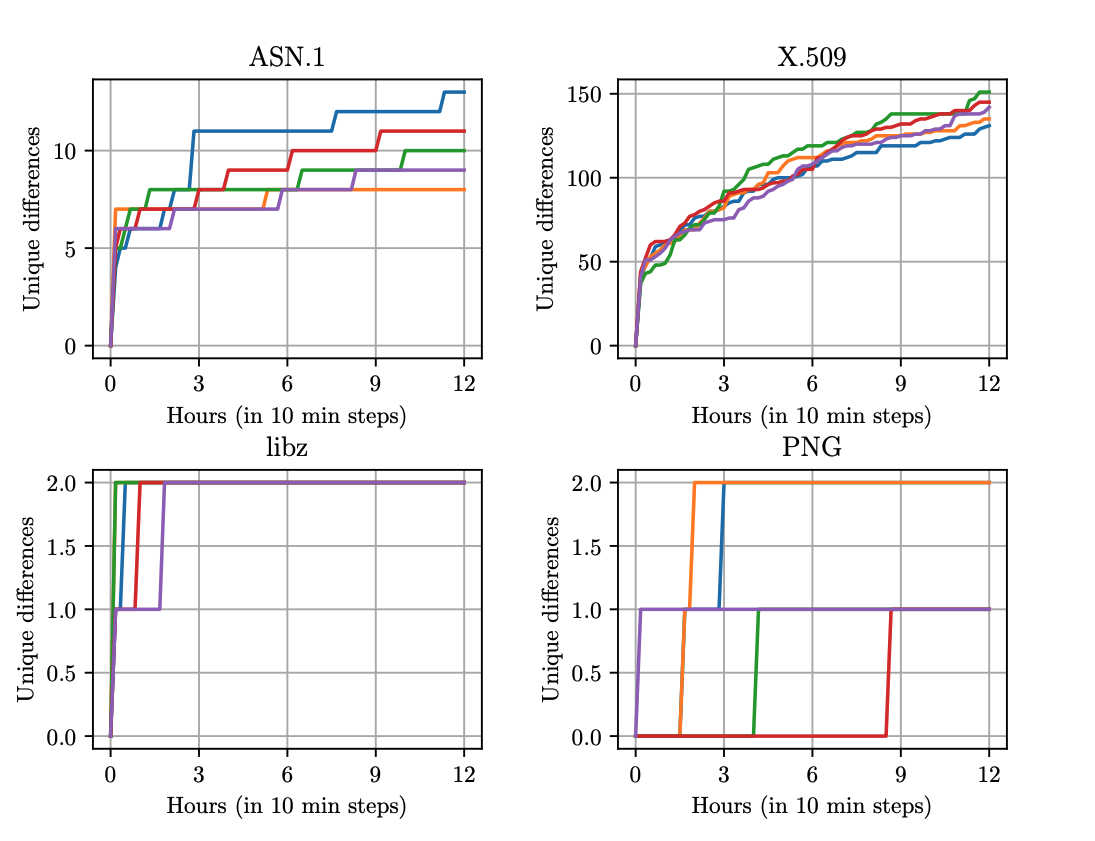
For this project we developed a differential fuzzer that compares parsers implemented in Go natively vs. parsers imported via cgo. We found that the choice whether to stay native or import is a hard one and hope to provide some guidance. As targets we picked four popular libraries: libcrypto, libpng, libssl, and libz - we found differences in parsing that can be exploited which we line out in two case studies. This work also resulted in a patch to Go compress/zlib.
GitHub package popularity
We also present an analysis of how prevalent unsafe, cgo, and assembly code are on popular GitHub repositories - they are more popular than we expected! C code was present in 54% of repositories and unsafe in 29%, 23% of repositories used both.
| Type | Repositories |
|---|---|
| Unsafe | 298 (29.77%) |
| C | 550 (54.95%) |
| S | 51 (5.09%) |
| C+Unsafe | 237 (23.68%) |
| C+S | 48 (4.80%) |
| S+Unsafe | 47 (4.70%) |
| C+S+Unsafe | 45 (4.50%) |
| No C or Unsafe | 390 (38.96%) |
| No C, S, or Unsafe | 389 (38.86%) |
| All | 1,001 (100%) |
Paper
Our paper is available now and will be presented at WOOT’23. This year WOOT is co-located with S&P in SF at the end of May.
