25 Jun 2023
Overview
Query parameters in URLs are sometimes useful, but often they are not.
For example, shared Twitter links have additional tracking information that have no functional advantage when sharing.
They can be removed manually when sending a link to someone, but that time accumulates.
To automate this I created an iOS shortcut to remove them when a link is in the clipboard to reduce the privacy impact.
iOS Shortcuts
Shortcuts is an iOS app that allows to combine actions on iOS without having to create standalone iOS apps.
The interface is simple enough that it can be used from a phone while creating useful tools.
The API is powerful, even something as simple as links directly into iOS settings can be a time saver.
In previous iterations the application was known as Workflow, and since iOS 13 Shortcuts are available as app installed by default.
Implementation
Links shared from Twitter have the following format:
https://twitter.com/(twitter-account)/status/(tweet-id)?s=...&t=(tracking-id)
In this case none of the query parameters serve a function other than tracking.
Treating the URL as a string stripping parameters is simple enough - keep everything before ? and discard the rest.
Conveniently iOS Shortcuts let us access the clipboard just like that, no parsing of the URL is necessary in this case.
For me this was the first time I used iOS shortcuts and I have to say that it is surprisingly easy to use.
We can pull data from the clipboard and apply regex directly to it, we match for content pre-question mark in URLs and write the match back to the clipboard - if any.
Since this URL pattern is not limited to Twitter I made the script remove all query parameters regardless of host.
Instagram, Amazon and others similarly use query parameters merely for tracking.
My shortcut is available here but it should be simple to reimplement manually.
Addendum
After putting this together I learned that iOS 17 will support such functionality natively, no shortcuts required.
This is a great feature and I’m glad it will arrive natively in iOS to boost user privacy a bit.
25 May 2023
Overview
In 1892 an anonymous artist in Germany drew the now famous duck/rabbit optical illusion.
It was soon popularized by psychologists and even Ludwig Wittgenstein.
To one person it will be a duck and others a rabbit.
What people see first is tied to their expectations and other mental models.
This situation is not limited to humans, computers have similar difficulties in parsing input.
Parsers in programming languages similarly can read the same input but draw different conclusions about what to make of the data.

Go
Go is a widely popular language for backend programming and powers large chunks of the internet.
Go comes with fresh implementations of many parsers, yet allows to import code written in C which is often used to include older parsers to Go programs.
When it comes to picking a parser, developers make a choice picking one over the other.
This choice is not well understood, as these parsers can disagree on certain inputs leading to diverting behavior.
We were wondering whether these divergences can be leveraged for security and correctness testing, and developed a differential fuzzer to study such effects and identify vulnerabilities.
Fuzzing
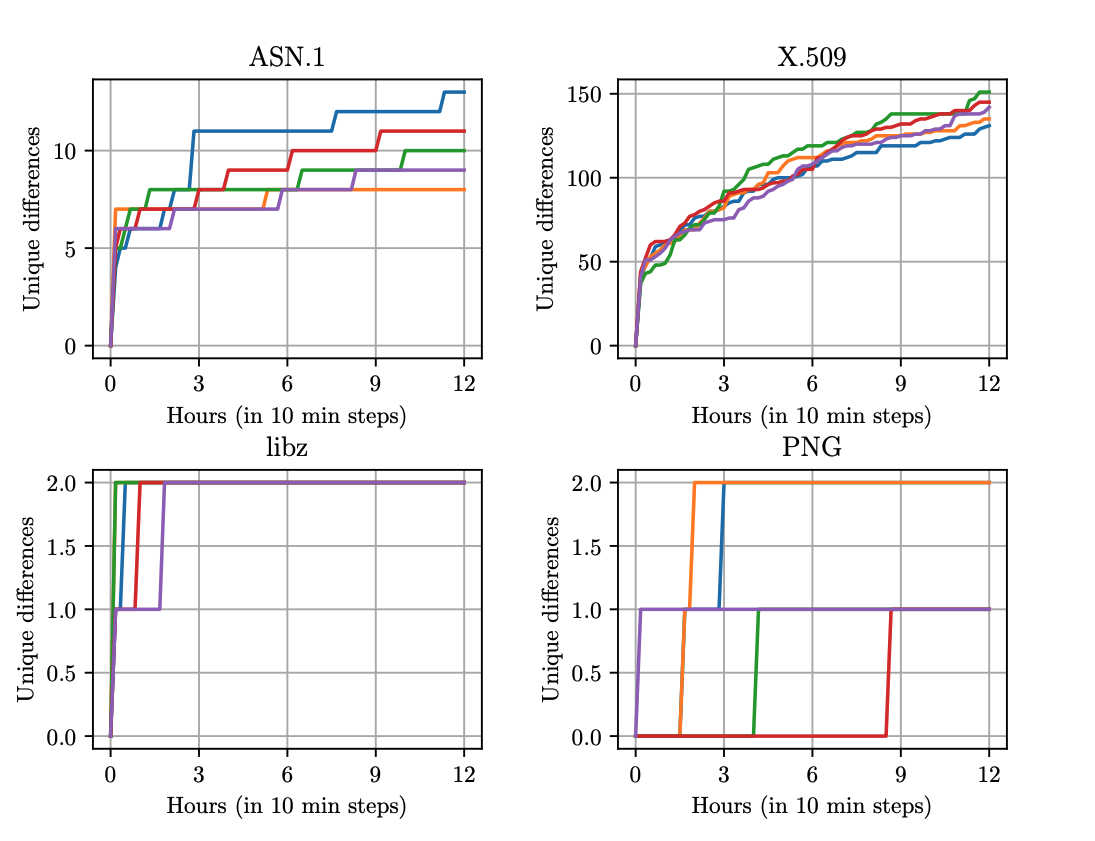
For this project we developed a differential fuzzer that compares parsers implemented in Go natively vs. parsers imported via cgo.
We found that the choice whether to stay native or import is a hard one and hope to provide some guidance.
As targets we picked four popular libraries: libcrypto, libpng, libssl, and libz - we found differences in parsing that can be exploited which we line out in two case studies.
This work also resulted in a patch to Go compress/zlib.
GitHub package popularity
We also present an analysis of how prevalent unsafe, cgo, and assembly code are on popular GitHub repositories - they are more popular than we expected!
C code was present in 54% of repositories and unsafe in 29%, 23% of repositories used both.
| Type |
Repositories |
| Unsafe |
298 (29.77%) |
| C |
550 (54.95%) |
| S |
51 (5.09%) |
| C+Unsafe |
237 (23.68%) |
| C+S |
48 (4.80%) |
| S+Unsafe |
47 (4.70%) |
| C+S+Unsafe |
45 (4.50%) |
| No C or Unsafe |
390 (38.96%) |
| No C, S, or Unsafe |
389 (38.86%) |
| All |
1,001 (100%) |
Paper
Our paper is available now and will be presented at WOOT’23.
This year WOOT is co-located with S&P in SF at the end of May.

19 May 2023
Block operates a service mesh with SPIFFE-compatible identity for backend workloads.
We recently implemented a system to onboard acquisitions to connect with the service mesh: Connecting Block Business Units with AWS API Gateway.
04 May 2023

I had the great opportunity to give a guest lecture at the Chalmers Security & Privacy Lab in Gothenburg, Sweden.
The talk was titled “Building a Secure Foundation”, more details here.
It was great to meet everyone!
20 Oct 2022
I had the opportunity to work on a recent product launch at Block/Square in collaboration with Apple: Tap to Pay on iPhone, which became available recently!
The project brings accepting NFC payments directly to iPhones.
It was a lot of fun to work on the project and with such a great team.
More details and how to activate are available here.