An extended edition of our HotFuzz work (conference publication at NDSS) has been published in the ACM Transactions on Privacy and Security.
This paper provides significantly more detail on resource exhaustion vulnerability discovery, covers both temporal and spatial attacks and discusses more discovered vulnerabilities.
Paper available from ACM via open access here.
AWS Lambdas have recently been extended with a new feature that adds a runtime environment before a Lambda is executed: Lambda extesions.
We have published a writeup on the Square Developer blog how we trialed this technology before it was generally available to prefetch secrets from Secrets Manager: Using AWS Lambda Extensions to Accelerate AWS Secrets Manager Access.
This work has also been covered in the AWS Compute Blog.
HotFuzz is a project in which we search for Algorithmic Complexity (AC) vulnerabilities in Java programs. These are vulnerabilities that can significantly slow down a program to exhaust its resources with small input. To use an analogy - it is easy to overwhelm a pizza place by ordering 100 pizzas at once, but can you think of a single pizza that would grind the restaurant's gears and bring operation to a halt?
We created a specialized fuzzer that ran on a customized JVM collecting resource measurements to guide programs towards worst-case behavior. We found 132 AC vulnerabilities in 47 top maven libraries and 26 AC vulnerabilities in the JRE including one in java.math that was reported and fixed as CVE-2018-1517.
Effects of exploiting an AC vulnerability can be similar to a Denial of Service attack. However, these are often linear in behavior - the attacker sends lots of requests that overwhelm the target system. For this project we are interested in attacks where input and effect are disproportional. For example, making one request and causing a program to be stuck in a loop exhausting it's CPU. There is some related work such as SlowFuzz or PerfFuzz. However, we decided this topic needs further exploration.
System
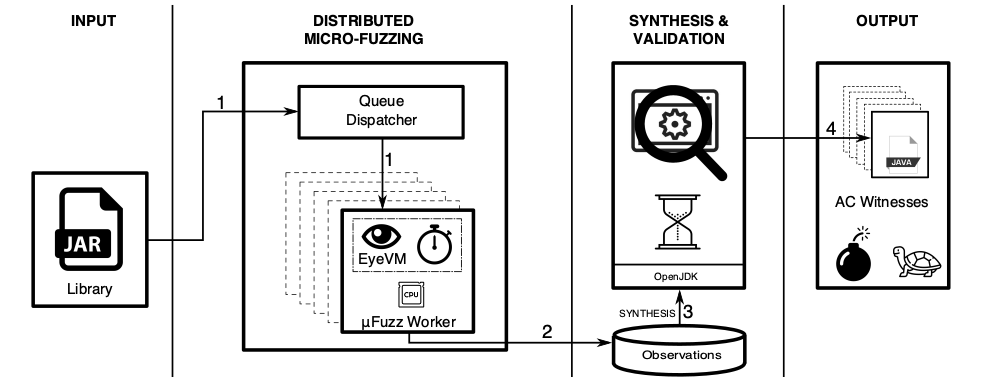
As opposed to fuzzing a program's main entry point, we fuzz all methods treating them as potential entry points. To generate input values for method parameters we use Small Recursive Instantiation (SRI) based on type signature. We recursively instantiate objects which can be passed into the method invocation, for primitive variables we generate values randomly. However, since uniform distributions are not ideal for Java objects we use a custom distribution which is described in the paper. These form the initial population for our genetic algorithm where we use CPU utilization as fitness function driving towards worst-case consumption. This process emulates natural selection where entities in a population are paired and produce cross-over offspring with some mutations. Typically fuzzers do cross-over on bit level, extending this technique to objects with type hierarchies is a central component of micro-fuzzing.
As baseline to compare against we used another instantiation approach called Identity Value Instantiation (IVI). For example: 0 for integer, empty string for strings, etc. IVI is the simplest possible value selection strategy possible and merely used to assess effectiveness of SRI.
For measurement microFuzz workers contain a custom JVM that is called EyeVM. EyeVM is built on top of OpenJDK with a HotSpot VM modified for measuring precise CPU consumption.
Output from micro-fuzzing is passed on to witness synthesis and validation where a generated program is run and measured on an unmodified JVM. This verification step reduces false positives where fuzzing causes programs to hang, for example polling a socket or file. The synthesized program calls the target method with help from the reflection API and the Google GSON library, using wall-clock to measure runtime.
HotFuzz system overview leading from jar file to AC witnesses
Results
We micro-fuzzed the JRE, the top 100 maven repositories, and challenges provided to us by DARPA. We found 132 AC vulnerabilities in 47 top maven libraries and 26 AC vulnerabilities in the JRE including one in java.math.
One finding that resulted in a CVE that was fixed by Oracle and IBM in their JRE implementations is CVE-2018-1517. HotFuzz found input to BigDecimal.add, which is an arbitrary precision library, that would lead to dramatically slowed down processing. In the case of IBM J9 we measured the process to be stuck for months. The cause for the slow down lies in how variables are allocated in the library. The bug and more results are presented in detail in the paper.
Other than comparing SRI with IVI fuzzing, a negative result that is not covered in the paper is that we also tried seeding fuzzing input with data from unit tests of libraries. These have not resulted in improved fuzzing results which was a surprise to us.
Summary
HotFuzz is a method-based fuzzer for Java programs that tries to drive input towards worst-case behavior in regards to CPU consumption. We found bugs in popular maven libraries and one CVE in java.math that lead to fixes by Oracle and IBM. The paper will be published at NDSS this year.