In this post I will provide some background information on the Kendall challenge of the Boston Key Party CTF. The focus is rather on how the challenge was designed than how to solve it. I'm sure others will cover that perspective in writeups.
This CTF is mostly run by BUILDS, but also with some challenges from others including Northeastern SecLab. The game board was organized by MBTA stations as a Google Maps layover, courtesy of Jeff Crowell.
The challenge categories were organized by train lines. The blue line was crypto, orange was reversing, red line was pwning. Everything else ended up on the green line.
For the Kendall challenge (pwning, 300 pts) we wanted to combine multiple tasks that require different skills into a single more complicated challenge. Also, we also wanted to create something around the recent Lenovo / Superfish news stories. However, creating a challenge titled "Super*" or "*fish" would have given away too much. We had to be more sneaky about this, but also avoiding giving away too little having players try to guess what to do.
We ended up with a combination of a remote exploitable router that leads on to man-in-the-middling a SSL connection that has the superfish certificate installed. Players were provided with IP/Port of the pwnable router and the binary that was running there.
A breakdown of the steps necessary to finish:
pwn the binary
Bypass authentication
Overwrite DNS entries with DNS controlled by team
Trigger DHCP renew
Intercept Browsing
Set up DNS server that responds with team's IP
Listen to the requests and make them succeed
Interpret the HTTP request
Set up SSL interception with Superfish CA
Part 1: The Router
The router software was remote accessible. When connecting, users were greeted by the following screen:
#####################################################
# DHCP Management Console #
# Auditing Interface #
#####################################################
h show this help
a authenticate
c config menu
d dhcp lease menu
e exit
[m]#
The user can operate as guest, anything important requires to be administrator. Read: there is an easy buffer overflow in the "filter" menu option, it allows to overwrite the admin flag. We included log files which hinted at the DHCP setting being important (it reads a static file). Players had to bypass authentication and then change the DNS to point to one of their machines. Next, trigger "renew leases". What happens in the background: the program will call another program in the same directory which pushes the DNS setting to something that drives the browser via sockets. This process will directly kick off an artificial browser that issues two web requests. We separated the accounts of the binary and the browser to make finding shortcuts to the flag harder.
Note: much of the work with the router binary was done by Georg Merzdovnik.
Part 2: The Browser
We simulated a user browsing websites. First a HTTP site, later log into their bank account where some sensitive information is revlealed (the flag). Should any step in this process fail, the browser aborts operation. The "browser" was a python script using urllib2. Parts that were important to get right were the DNS queries and certificate validation. The DNS lookups had to be performed through the server the teams provide by owning the router only. The SSL request verifies against the superfish certificate only. By default urllib2 will not check authenticity of certificates.
Once teams pushed their IP address as DNS server, they could see two incoming DNS queries. One for yandex.ru and the second one for a made up hostname "my.bank"
Next, players had to reply with an IP they control and have a running web server to intercept the requests. For my local testing I used minidns, a dependency-free python script that will resolve any hostname to a single IP address.
One thing I dislike while solving challenges is pointless guessing. So, before making a HTTPS request we issued a HTTP request to give a hint what to do with the SSL connection. We added a new header, namely "X-Manufacturer" with the value "Lenovo". This is a completely made up header which was supposed to be a hint towards Superfish without being blatantly obvious.
The second request was pointed at "https://my.bank" Teams had to make the browser establish a legitimate SSL connection and we would issue a request to: "https://my.bank/login/username={0}".format(self.FLAG)
Although we had no specific format for keys, we decided to prefix the key with "FLG-" to make it obvious once players got that far.
To get this right, teams could either run a web server with the Superfish private key, or MITM and point the request somewhere else.
A writeup using sslsplit for the latter option is available on Rob Graham's blog.
Closing
The source code of the challenges will be released as a tarball at some point in the near future, follow @BKPCTF (or me) for updates. I hope the challenge was fun and am looking forward to hear in writeups how teams did it.
In December 2012, I was curious who is using Content Security Policy, and how are they using it?
Content Security Policy (CSP) can help websites to get rid of most forms of content injection attacks. As it is standardized and supported by major browsers, we expected websites to implement it. To us, the benefits of CSP seemed obvious.
However, as we started to look into the CSP headers of websites, we noticed that few of them actually used it. To get a better overview we started crawling the Alexa Top 1M every week. What started out as a just-for-fun project escalated to a data collection of over 100GB of HTTP header information alone. We are publishing the results in our (Michael Weissbacher, Tobias Lauinger, William Robertson) paper Why is CSP Failing? Trends and Challenges in CSP Adoption at RAID 2014.
We investigated three aspects of CSP and its adoption. First, we looked into who is using CSP and how it is deployed. Second, we used report-only mode to devise rules for some of our websites. We tried to verify whether this is a viable approach. And third, we looked into generating content security policies for third-party websites through crawling, to find obstacles that prevent wider deployment.
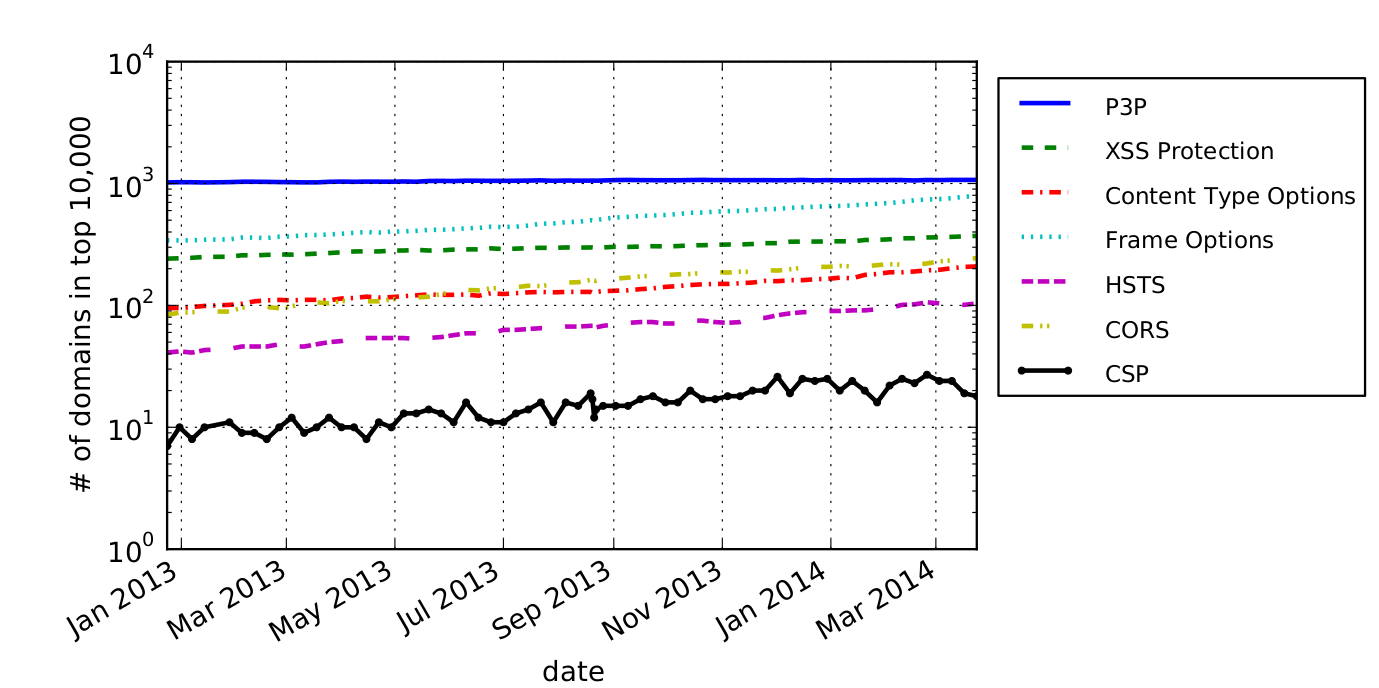
CSP headers in comparison to other security relevant headers
We have found that CSP adoption significantly lags behind other web security mechanisms and that, even when it has been adopted by a site, it is often deployed in a way that negates its theoretical benefits for preventing content injection and data exfiltration attacks. While more popular websites are more likely to use it, only 1% of the 100 most popular websites use it on their front page.
To summarize our findings:
Out of the few websites using CSP, the policies in use did not add much protection, marginalizing the possible benefits.
The structure of sites, and in particular integration of ad networks, can make deployment of CSP harder.
CSP can cause unexpected behavior with Chrome extensions, as we detail below.
The project resulted in fixes to phpMyAdmin, Facebook and the GitHub blog.
In our paper, we suggest several avenues for enhancing CSP to ease its adoption. We also release an open source CSP parsing and manipulation library.
Below, we detail on some topics that did not fit into the paper, including bugs that we reported to impacted vendors.
Chrome Extensions
Chrome enforces CSP sent by websites on its extensions. This seems well known, but comes with a couple of side effects. The implications are that CSP from websites can break functionality of extensions, intentionally or unintentionally. Other than that, it makes devising CSP rules based on report-only mode very cumbersome, due to lots of bogus reports. Enforcing rules on extensions seems surprising, especially since they can request permission to modify HTTP headers and whitelist themselves. In fact, we found one such extension that modifies CSP headers in flight.
Recovering granularity of CSP reports
While older versions of Firefox will report specifically whether an eval or inline violation occurred, newer versions of any browser won’t. We provide a work-around to detect such errors in the paper, this involves sending multiple headers and post-processing the reports.
Facebook
With Facebook, we noticed that headers (including CSP) were generated based on the user agent. This has some advantages, e.g., sending less header data to browsers that don’t support certain features. Also, Firefox and Chrome were sent different CSP headers (the difference being, the Skype extension was whitelisted for Chrome.) We also noticed that for some browser versions, no CSP rules were sent out. The likely reason is that CSP handling in some browser versions is buggy. For example, Chrome enforces eval() even in report-only mode in some versions. However, due to misconfiguration, CSP was only served to browser versions before the bugs were introduced, and none after. As a result, CSP was only in use for a fraction of browsers that in fact support it. After we informed them of this, Facebook quickly fixed the issue. Now, CSP is being served to a wider audience of browsers than before. Also, we were added to the Whitehat “Thanks” list.
phpMyAdmin
We found that phpMyAdmin, which serves CSP rules by default, had a broken configuration on it’s demo page. The setup prevented loading of Google Analytics code. This turned out to be interesting, as the script was whitelisted in the default-src directive, but script-src was also specified and less permissive. Those two are not considered together, and the more specific script-src directive overrode default-src. Hence, including the Google analytics code was not allowed and resulted in an error. We pointed out the issue and it resulted in a little commit.
GitHub
We used several sites that deploy CSP as benchmark to test our tool for devising CSP rules. With GitHub, we noticed that our tool came up with more directives than the site itself. After investigating, we found that one of the sites on their blog was causing violations with the original rules, as it tried to include third party images. This was interesting, as any site which specifies a report-uri would have caught this, but GitHub doesn’t use the feature. While this caused no security issue, it stopped the blog post from working as intended. With report-uri enabled that mistake would have popped up in the logs and could have been fixed instantly. We think this highlights how important usage of the report-uri is. In summary, this was more of an interesting observation about report-uri to us than a problem on their side.
The 2012 Qualification round for CSAW CTF was fun. I was playing with the Northeastern Seclab hacking group - PTHC. One of the more interesting challenges was networking 300.
As input we received a file called "dongle.pcap", no further description.
The first thing to do with pcaps is to load them in wireshark. The type for most packets is URB_Interrupt or URB_Control (URB is a USB request block). Most of the packets don't look interesting - by browsing we found packet 67 which contains the following string: "Teensy Keyboard/Mouse/Joystick", this made us assume that we have to deal with recovering key presses.
Some quick googling lead us to this website, we downloaded the source files and inspected the code to analyze the protocol. We figured out that the packets we are interested in are pretty specific, they should be:
- 72 bytes long
- the 10th byte is \x01
- the 12th one is \x1a
- the 66th byte should be non-zero
- also we only care about the last 8 bytes and can disregard the rest
import binascii
from scapy.all import *
dongle = rdpcap("dongle.pcap")
for d in dongle:
sd = str(d)
if len(sd) == 0x48 and sd[9] == '\x01' and sd[11] == '\x1a':
x = sd[len(sd) -8:]
print binascii.hexlify(x)
This leaves us with 1338 packets, the last four bytes are all \x00. We inspect the file usb_keyboard_debug.h from the keyboard's source file and can see the key mapping. "A" = 4 etc. We created a mapping keycode-output and prepended it to our script so we would see the keyboards behavior. By inspecting the pcap we found that there were no ALT or STRG key presses, only shift and only for a couple of keys (3). For the sake of simplicity we decided just to check for these three cases in additional if clauses without making a generalized upper-case function. What we get from running the updated program:
The string "KEY{...}" made us assume we finished, but the scoreboard disagreed. It took us a while to figure out that we also have to take the RXTERM lines into account - the last two numbers (separated by "+" are the coordinates). That was the last part of the puzzle and we got the points.
The following program is the cleaned up, final version that will parse the pcap file, pull out the key presses, write the keys into a matrix with the corresponding coordinates and print them in order.
from scapy.all import *
import binascii
keys = {}
keys[4]='A'
keys[5]='B'
keys[6]='C'
keys[7]='D'
keys[8]='E'
keys[9]='F'
keys[10]='G'
keys[11]='H'
keys[12]='I'
keys[13]='J'
keys[14]='K'
keys[15]='L'
keys[16]='M'
keys[17]='N'
keys[18]='O'
keys[19]='P'
keys[20]='Q'
keys[21]='R'
keys[22]='S'
keys[23]='T'
keys[24]='U'
keys[25]='V'
keys[26]='W'
keys[27]='X'
keys[28]='Y'
keys[29]='Z'
keys[30]='1'
keys[31]='2'
keys[32]='3'
keys[33]='4'
keys[34]='5'
keys[35]='6'
keys[36]='7'
keys[37]='8'
keys[38]='9'
keys[39]='0'
keys[41]='ESC'
keys[43]='TAB'
keys[45]='-'
keys[46]='EQUAL'
keys[47]='LEFT_BRACE'
keys[48]='RIGHT_BRACE'
keys[49]='BACKSLASH'
keys[50]='NUMBER'
keys[51]='SEMICOLON'
keys[52]='QUOTE'
keys[53]='TILDE'
keys[54]='COMMA'
keys[55]='PERIOD'
keys[56]='SLASH'
keys[57]='CAPS_LOCK'
keys[58]='F1'
keys[59]='F2'
keys[60]='F3'
keys[61]='F4'
keys[62]='F5'
keys[63]='F6'
keys[64]='F7'
keys[65]='F8'
keys[66]='F9'
keys[67]='F10'
keys[68]='F11'
keys[69]='F12'
keys[72]='PAUSE'
keys[74]='HOME'
keys[75]='PAGE_UP'
keys[76]='DELETE'
keys[77]='END'
keys[79]='RIGHT'
keys[80]='LEFT'
keys[81]='DOWN'
keys[82]='UP'
keys[83]='NUM_LOCK'
keys[89]='KEYPAD_1'
keys[90]='KEYPAD_2'
keys[44]=' '
keys[40]='ENTER'
dongle = rdpcap("dongle.pcap")
buf = {}
buf[1] = ""
for d in dongle:
sd = str(d)
if len(sd) == 0x48 and sd[9] == '\x01' and sd[11] == '\x1a' and sd[0x42] != '\x00':
x = sd[len(sd) -8:]
# only these three keys get used with shift
if x[0] == '\x02':
if keys[ord(x[2])] == "EQUAL":
key = "+"
elif keys[ord(x[2])] == "RIGHT_BRACE":
key = "}"
elif keys[ord(x[2])] == "LEFT_BRACE":
key = "{"
else:
key = keys[ord(x[2])]
if key == "ENTER":
print buf[len(buf)]
buf[len(buf)+1]=""
key = "\n"
else:
buf[len(buf)] += key
# putting keys on their corresponding coordinates
matrix = {}
for i in range(1,len(buf),2):
(a,b,c) = (buf[i]).split("+")
if int(c) not in matrix.keys():
matrix[int(c)] = {}
# look ahead for one line - the echo command
matrix[int(c)][int(b)] = buf[i+1][-1:]
# print pressed keys in order
for x in sorted(matrix.keys()):
for y in sorted(matrix[x].keys()):
print "{a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6}03d-{a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6}03d-{a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6}s" {a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6} (x,y,matrix[x][y])
This weekend PPP organized its second PlaidCTF which was a lot of fun. Below is a quick writeup for the bittorrent forensics challenge.
Description:
It turns out that robots, like humans, are cheap and do not like paying for their movies and music. We were able to intercept some torrent downloads but are unsure what the file being downloaded was. Can you figure it out?
Provided was a file torrent.pcap, we used tshark (the command line tool for wireshark) to extract data from the packet capture. The only interesting data points are bittorrent.piece, from those we only need index, begin and data. By printing them in this order we can run a simple sort to make sure the file contents are in order.
Next we strip everything but the data field and the colons. Finally we use translate and sed to turn the hex representation into binary. After running the below script we have a file binout.
By using the file command and consequently unpacking we figure out its a bz2-ed tar file. Inside we find the files key.mp3 and key.txt. key.txt contains "t0renz0_v0n_m4tt3rh0rn", which turned out to be the valid key. We couldn't extract any hidden information from key.mp3 :-)
Note: if you are trying to reconstruct a file from a bittorrent pcap you might want to check for retransmits, missing indices, multiple files in one capture etc. It would make sense not to strip the headers directly with sed but keep them and run some script to analyze them.
I’d like to present a quick and dirty solution to comparing two JavaScript programs that can’t be compared with a simple diff. This can be useful to check whether programs are mostly equal and can help in figuring out where these differences are. The result will be achieved by performing a makeshift parse tree comparison.
Tools that will be used:
Google Closure Compiler
a small Perl script
vimdiff
First, Google’s Closure Compiler will be used to generate the parse trees.
The sourcename attribute should be stripped from the resulting file. Actually for most comparisons I did it was sufficient to keep only the first word of each line. This script can be used to print only the first word, but preserve heading whitespace (whitespace should be kept to keep a better overview later):
Suspicious blocks can be traced back to the parse tree before it was stripped (same line number). From there the surrounding function or variable names will lead back to the code in the JavaScript file.