In this post we introduce Ex-Ray, our recently developed system. We use it to detect browser extensions which leak browsing history, regardless of their leakage channel. After analyzing Chrome extensions with more than 1,000 installations (10,691 total) we flagged 212 as leaking. We also found two extensions with large installation base that leak the users' history by means that were undetectable to prior work.
Our paper "Ex-Ray: Detection of History-Leaking Browser Extensions" is available for download here: pdf and bib. This project was a collaboration between Northeastern University and University College London. We will present the work at ACSAC this December.
The browser has become the primary interface for interactions with the Internet, from writing emails, to listening to music, to online banking. The shift of applications from the desktop to the Web has made the browser the de-facto operating system. Browser extensions can "extend" the core functionality of the browser, across all online activities of a user. They sometimes pave the way towards features which later become integrated into browsers themselves, such as password managers.
However, the access to powerful APIs given to extensions also allows for undesired side effects, such as invasion of privacy. This project is partially motivated by our previous analysis into the SimilarWeb browsing history data collection. We found 42 extensions that reported all of users' browsing history to a third party, often without it being required by the advertised functionality or disclosed in the terms of service.
This motivated us to investigate further and develop a more general detection system for privacy leaks in browser extensions. We wanted an approach that captures fundamental invariants of tracking browsing behavior that would be robust against obfuscation or encryption. Ex-Ray operates with two complementary systems in supervised and unsupervised fashion, and a triage system that would ease manual verification. We flagged 212 as history-leaking and discovered extensions that were leaking in ways that were out of scope for prior work. One extension was using strong encryption on tracking beacons before transfer, and the other one was using WebSockets. As our system works independently of the way of leaking, we were able to flag both.
Honeypot Probe
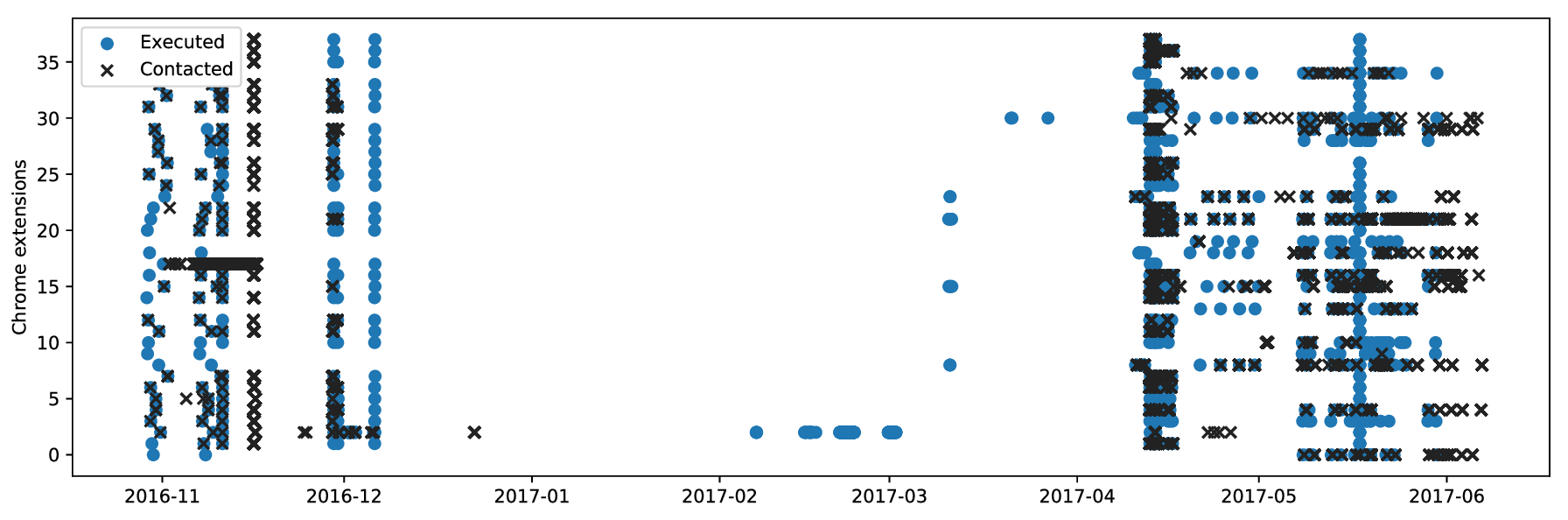
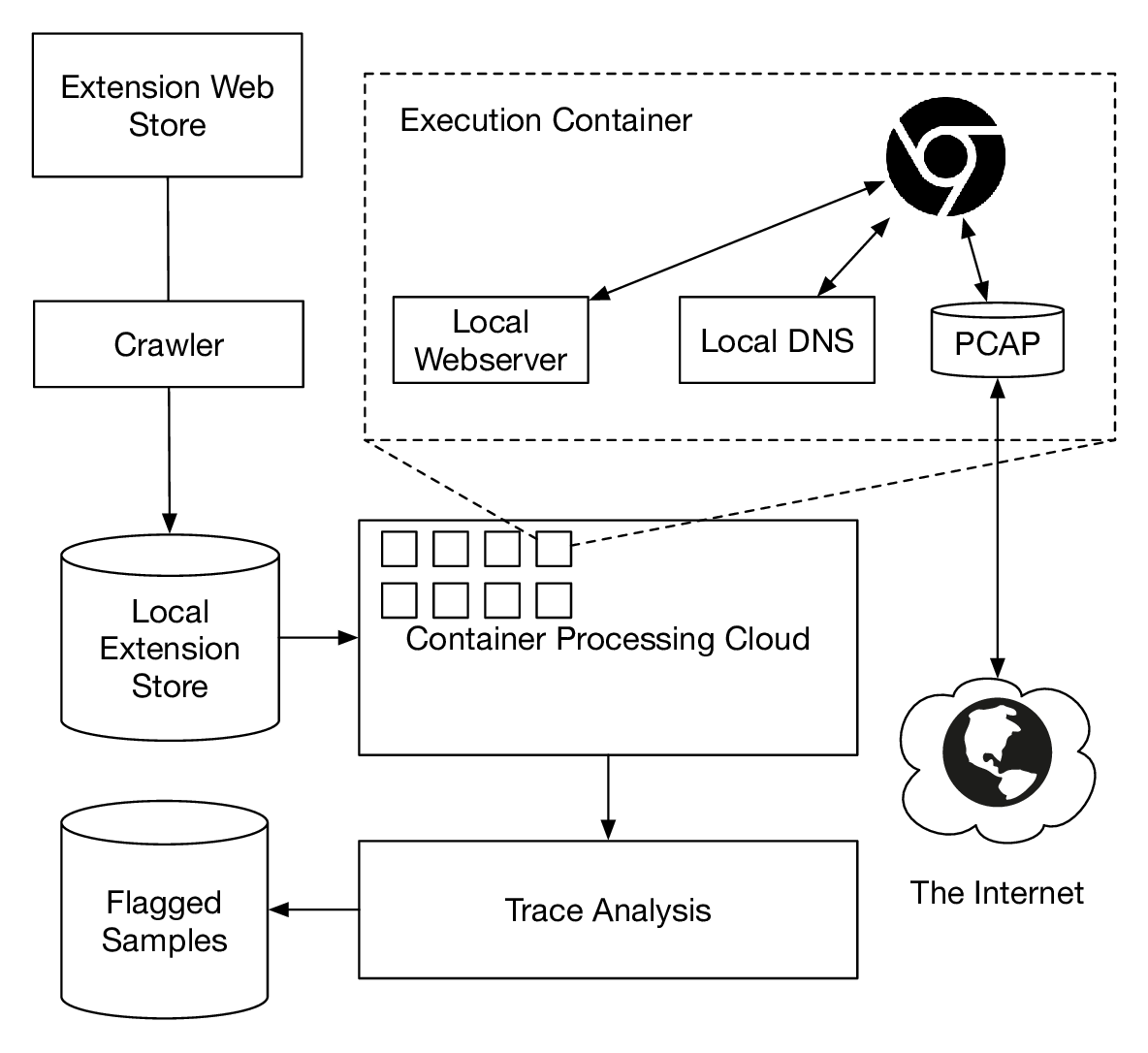
To gain insight into the environment in which trackers operate, and how data might be used, we configured a honeypot. We exercised extensions in a container and browsed by serving sites locally. Both Web and DNS were configured to work without interacting with the public Internet, except if extensions purposefully did so. We also operated a webserver with the same address on the public Internet that would collect incoming requests. As we encoded the extension ID into the URLs we visited, we were able to link incoming requests to extensions that have leaked them. After excluding VPN and proxy extensions, we found 38 extensions that would connect back to our honeypot. The confirmation that trackers are acting on leaked data motivated further steps in this work. We used these extensions as part of our ground truth for further experiments.
Here we compare extension execution to incoming request over time. We noticed that leaked history is often used immediately after it leaks to crawl the sites. These connections confirm that leaked browsing history is used by the receivers and is not leaked purely coincidentally. However, we identified no malicious behavior in our log files, such as vulnerability scans.
ABC ad blocking China special edition [translated]
CTRL-ALT-DEL new tab
Desprotetor de Links
Pop up blocker for Chrome
Similar Sites
nat-service.aws.kontera.com
Chistodeti
Woopages
199.175.48.183
static.36.51.9.176.clients.your-server.de
Other than the behavior over time, another aspect is possible collaboration between extension authors. In our honeypot probe we observed hosts that connected to multiple URLs unique to extensions, and conversely URLs that received connections from multiple hosts. These relations are possible indicators for a form of data sharing or shared infrastructure between trackers. Each line in this table consists of such a connected group.
System Description
Our system has three main components.
Unsupervised learning: based on counterfactual analysis on network traffic over multiple executions, we detect history-stealing extensions.
Triage-based analysis: A scoring system that can highlight extensions which have suspicious traffic behavior. It can be used as a pre-processing step to manually vet extensions.
Supervised learning: Using a labeled dataset from previous experiments, we can systematize identification of suspicious extensions. We build a model that detects leaks based on APIÂ calls.
In this post we will focus on the unsupervised learning component, for the other components we refer to the paper.
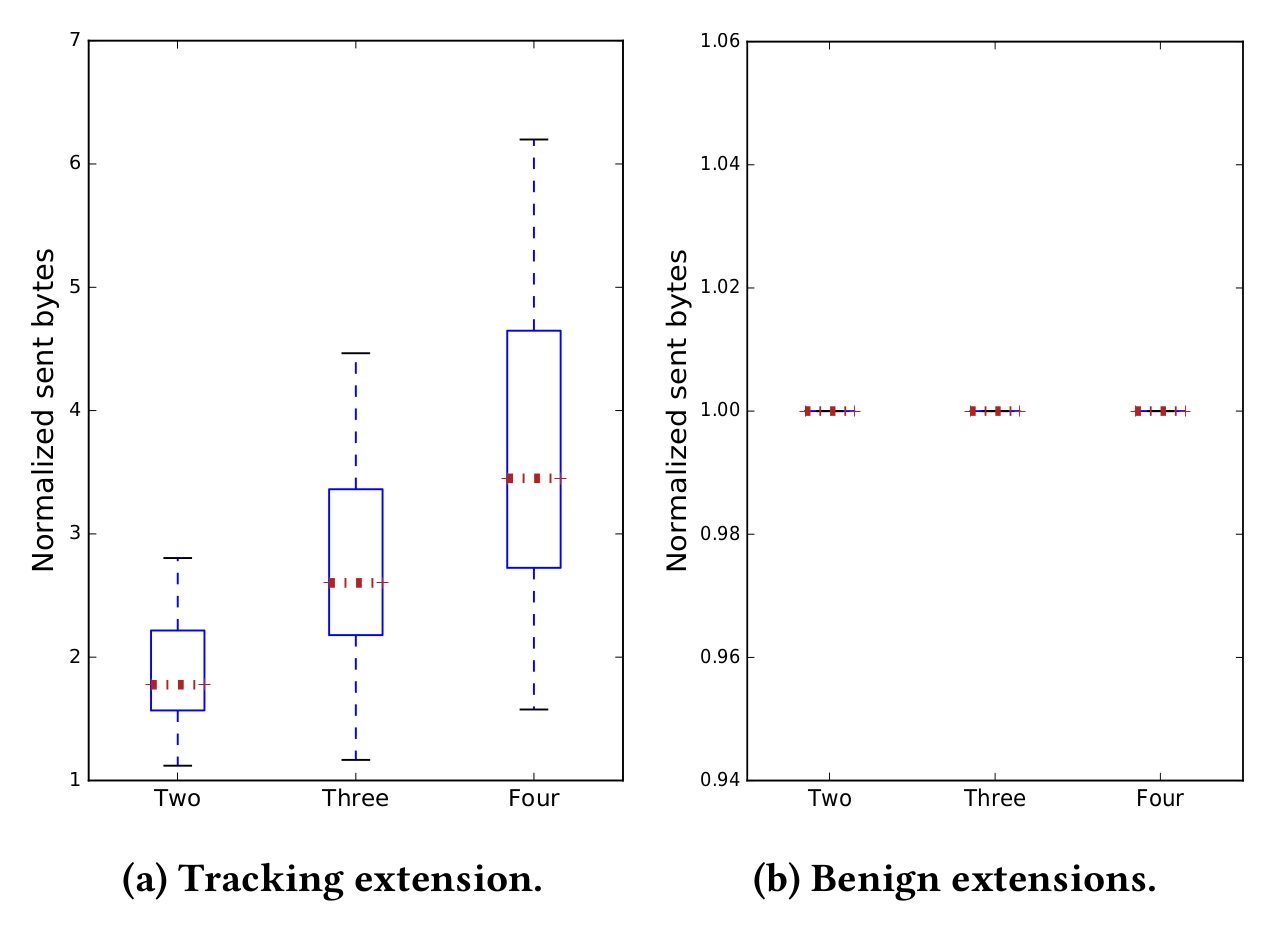
Comparison of sent traffic over several execution stages with increasing amount of history. On the Left we see history-leaking extensions, and on the right benign ones. Data that is sent out by extensions varies little for benign extensions, but for trackers it will vary depending on the amount of history supplied.
To identify privacy-violating extensions, we exercise them in multiple stages, changing the amount of private data supplied to the browser, and in turn to the extension under test. Based on the type of extension, the traffic usage can change depending on the number of visited sites. However, the underlying assumption is that benign extension traffic should not be influenced by the size of the browsing history.
Based on this insight, We use linear regression on each set of flows to estimate the optimal set of parameters that support the identification of history-leaking extensions. We aim to establish a causality relation between two variables: (i) the amount of raw data sent through the network and (ii) the amount of history leaked to a given domain. For this, we rely on the counterfactual analysis model. We use the size of history we provide to an extension as input variable to a controlled environment. Next, we observe outgoing traffic as an output variable for our classification. We also use other indicators such as lower bound of compressed history as cut-off value. The details of our detection engine are described in detail in the full paper (see links at top and bottom of post).
Ex-Ray extension execution overview. After downloading extensions from the Chrome Web Store, we exercise them in containers to collect traces for classification. To support our honeypot experiment we only access Web and DNS locally. As the subdomains we use are unique per extension and we keep the connections local to a container, leaks can be linked to the extension under test.
Results
In total, Ex-Ray flagged 212 Chrome extensions as history-leaking. This included two extensions which were undetectable to prior work. Web of Trust uses strong encryption (RC4) on extension level, before transfering data via HTTPS. Coupon Mate is an extension that leaks browsing history via WebSockets, which is used by 0.96% of extensions that we analyzed. Prior work uses keyword analysis on particular protocols, which would not have triggered on these two extensions.
Our dataset of flagged extensions and a triage report are available in our repository.
The amount of extensions leaking history is troublesome, in particular as this is possible for extensions with only modest permission access. While tracking on websites is prevalent, websites have to opt-in for it and solutions exist that allow users to remove them (e.g., Ghostery). Conversely, tracking in browser extensions covers all visited websites and no opt-out mechanism exists. This behavior does not seem to be monitored for in extension stores.
Takeaways
Our key takeaways from this project are as follows:
It is easy for a browser extension to monitor and report browsing to a third party without requesting suspicious permissions.
Extensions utilize leaking channels that have not been considered by state-of-the-art leak detection before.
Leaking behavior can be detected in a robust way with a combination of supervised and unsupervised methods, for example with a system such as Ex-Ray
Extension stores should monitor for such behavior and alert users of history leaks.
As a general precaution, users should be careful when installing browser extensions, as stores do not monitor for such behavior currently.
Conclusion
We introduce a new method for detection of privacy-violating browser extensions, independently of their protocol, and developed a prototype system: Ex-Ray. Our system uses a combination of supervised and unsupervised methods to identify features characteristic to leaking extensions. We analyzed all extensions from the Chrome Web store with more than 1,000 installations (10,691 total) and flagged 212 extensions as history-leaking. Two extensions that we flagged were leaking history in previously undetectable ways. We suggest that extensions should be both tested more rigorously when admitted to the store, as well as monitored while they execute within browsers. Our paper is available for download here: ( pdf and bib ).
This post describes how to do function-level instrumentation of JavaScript programs using a Closure Compiler fork which is available here. The repository contains all code used here in the instrumentation-sample directory. Program points that can be hooked are function definition, invocation, and exit. Closure supports instrumentation internally as-is, this fork makes it more useful. Since Closure is already a popular part of JS build chains, it was an attractive target to add this feature to. I used this code as part of a project for JS hardening (ZigZag).
Update: The code has been merged into the official Closure repository.
instrumentation_template FILE is the new option. The specified file contains the code that will be added to the JS file.</p>
Code specified as `"init"` will be prepended to the program, this is where function definitions for the report call/exit/defined functions go. The other three types: report_call, report_exit and report_defined specifiy the functions that should be invoked for those actions. These functions are where one wants to fill in the blanks with one's own code to see what's happening in a program.
Here is a bare-bones instrumentation template:
`fun_id` is a unique identifier of functions within the program. The report_exit function will be used in a return statement. It is important to keep in mind that user specified function has to return the return argument (`return_value`), otherwise the instrumented program will not work as hoped for. When compiling a program that consists of one function:
# Accessing arguments
An example that is more interesting would be logging arguments used in a function call. For that, the arguments variable can be used. Since this variable is not defined in the script otherwise, it needs to be defined as an extern. The externs file contains only one line: "arguments". To instrument the program, the command line has to be extended by:
`--externs externs.txt --jscomp_off=externsValidation`
The updated code for the `"init"` section of the instrumentation template:
# Closing
This post explains how to use a modified version of Closure Compiler to instrument programs via templates. I found it a pity Closure doesn't allow for easier instrumentation out of the box, and hope this code can be useful to others working with JavaScript.
In December 2012, I was curious who is using Content Security Policy, and how are they using it?
Content Security Policy (CSP) can help websites to get rid of most forms of content injection attacks. As it is standardized and supported by major browsers, we expected websites to implement it. To us, the benefits of CSP seemed obvious.
However, as we started to look into the CSP headers of websites, we noticed that few of them actually used it. To get a better overview we started crawling the Alexa Top 1M every week. What started out as a just-for-fun project escalated to a data collection of over 100GB of HTTP header information alone. We are publishing the results in our (Michael Weissbacher, Tobias Lauinger, William Robertson) paper Why is CSP Failing? Trends and Challenges in CSP Adoption at RAID 2014.
We investigated three aspects of CSP and its adoption. First, we looked into who is using CSP and how it is deployed. Second, we used report-only mode to devise rules for some of our websites. We tried to verify whether this is a viable approach. And third, we looked into generating content security policies for third-party websites through crawling, to find obstacles that prevent wider deployment.
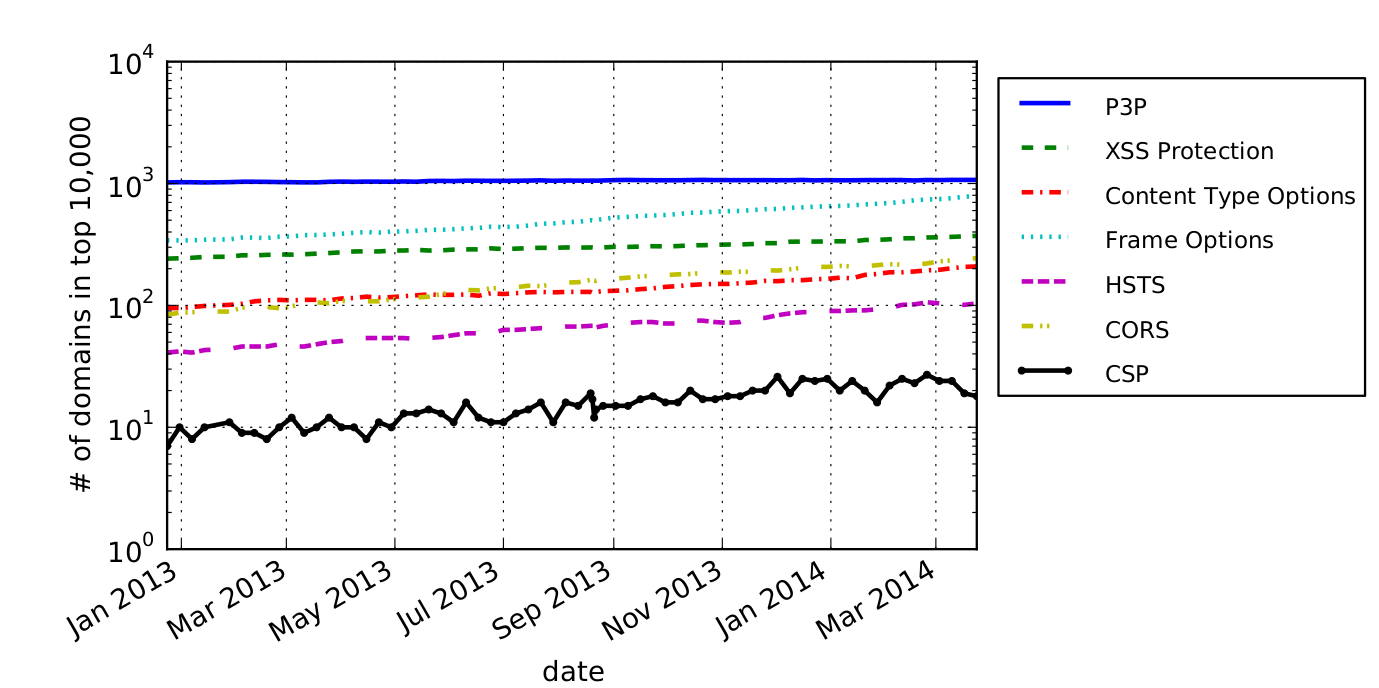
CSP headers in comparison to other security relevant headers
We have found that CSP adoption significantly lags behind other web security mechanisms and that, even when it has been adopted by a site, it is often deployed in a way that negates its theoretical benefits for preventing content injection and data exfiltration attacks. While more popular websites are more likely to use it, only 1% of the 100 most popular websites use it on their front page.
To summarize our findings:
Out of the few websites using CSP, the policies in use did not add much protection, marginalizing the possible benefits.
The structure of sites, and in particular integration of ad networks, can make deployment of CSP harder.
CSP can cause unexpected behavior with Chrome extensions, as we detail below.
The project resulted in fixes to phpMyAdmin, Facebook and the GitHub blog.
In our paper, we suggest several avenues for enhancing CSP to ease its adoption. We also release an open source CSP parsing and manipulation library.
Below, we detail on some topics that did not fit into the paper, including bugs that we reported to impacted vendors.
Chrome Extensions
Chrome enforces CSP sent by websites on its extensions. This seems well known, but comes with a couple of side effects. The implications are that CSP from websites can break functionality of extensions, intentionally or unintentionally. Other than that, it makes devising CSP rules based on report-only mode very cumbersome, due to lots of bogus reports. Enforcing rules on extensions seems surprising, especially since they can request permission to modify HTTP headers and whitelist themselves. In fact, we found one such extension that modifies CSP headers in flight.
Recovering granularity of CSP reports
While older versions of Firefox will report specifically whether an eval or inline violation occurred, newer versions of any browser won’t. We provide a work-around to detect such errors in the paper, this involves sending multiple headers and post-processing the reports.
Facebook
With Facebook, we noticed that headers (including CSP) were generated based on the user agent. This has some advantages, e.g., sending less header data to browsers that don’t support certain features. Also, Firefox and Chrome were sent different CSP headers (the difference being, the Skype extension was whitelisted for Chrome.) We also noticed that for some browser versions, no CSP rules were sent out. The likely reason is that CSP handling in some browser versions is buggy. For example, Chrome enforces eval() even in report-only mode in some versions. However, due to misconfiguration, CSP was only served to browser versions before the bugs were introduced, and none after. As a result, CSP was only in use for a fraction of browsers that in fact support it. After we informed them of this, Facebook quickly fixed the issue. Now, CSP is being served to a wider audience of browsers than before. Also, we were added to the Whitehat “Thanks” list.
phpMyAdmin
We found that phpMyAdmin, which serves CSP rules by default, had a broken configuration on it’s demo page. The setup prevented loading of Google Analytics code. This turned out to be interesting, as the script was whitelisted in the default-src directive, but script-src was also specified and less permissive. Those two are not considered together, and the more specific script-src directive overrode default-src. Hence, including the Google analytics code was not allowed and resulted in an error. We pointed out the issue and it resulted in a little commit.
GitHub
We used several sites that deploy CSP as benchmark to test our tool for devising CSP rules. With GitHub, we noticed that our tool came up with more directives than the site itself. After investigating, we found that one of the sites on their blog was causing violations with the original rules, as it tried to include third party images. This was interesting, as any site which specifies a report-uri would have caught this, but GitHub doesn’t use the feature. While this caused no security issue, it stopped the blog post from working as intended. With report-uri enabled that mistake would have popped up in the logs and could have been fixed instantly. We think this highlights how important usage of the report-uri is. In summary, this was more of an interesting observation about report-uri to us than a problem on their side.
I’d like to present a quick and dirty solution to comparing two JavaScript programs that can’t be compared with a simple diff. This can be useful to check whether programs are mostly equal and can help in figuring out where these differences are. The result will be achieved by performing a makeshift parse tree comparison.
Tools that will be used:
Google Closure Compiler
a small Perl script
vimdiff
First, Google’s Closure Compiler will be used to generate the parse trees.
The sourcename attribute should be stripped from the resulting file. Actually for most comparisons I did it was sufficient to keep only the first word of each line. This script can be used to print only the first word, but preserve heading whitespace (whitespace should be kept to keep a better overview later):
Suspicious blocks can be traced back to the parse tree before it was stripped (same line number). From there the surrounding function or variable names will lead back to the code in the JavaScript file.
One of my iCTF challenges was a simple JavaScript obfuscation, a backup of the code is available here. What happens is obvious, window.alert is triggered with the message “why?”. “Why” is less obvious since the code was encoded with jjencode. There are no other visible hints.
To further look into window.alert, we can overwrite the function:
FYI: Before the obfuscation the code looked like this:
varobj={};obj.secret="Angelina Jolie's only good movie, in leet speak, reverse is the key";obj.toString=function(e){return"why?";};obj.toSource=function(e){return"function toSource() {\n"+" [native code]\n"+"}\n"};window.alert(obj);