The pie chart is a very successful way of displaying proportions. However, it was never properly named by it's inventor William Playwright.
It has different names in different languages, but apparently often based on food. Pie in English, Cake in German, Pizza in Portuguese, and Camembert in Frech. This sparked my interest what else is out there. To solve this, I made a short Google Cloud program to translate "pie chart" to 103 different languages and back. I found that there are more odd cases than Camembert, such as "cookies" in Hmong, "skin" in Samoan, or "chart chart" Kazakh. These results are established via Google Cloud Translate only and not verified by native speakers.
Depiction of a Camembert. Or a pie. What's the difference really? File from Wikipedia: https://en.wikipedia.org/wiki/Camembert
Introduction
Pie charts are roughly 200 years old and are a very popular form of displaying proportions. Also, pie charts were not properly named when they were introduced.
Many of the names used for this chart around the world are based on food. For example, in German "pie chart" translates to "Tortendiagramm" which literally translated would be a "cake diagram". What prompted this investigation was this tweet. This post digs a bit into this phenomenon but I was curious whether I can go further. I thought there must be more to pie charts around the world.
Translations
As the year is 2019, all such investigations must involve the cloud. Therefore I used the Google Cloud Translate API to explore the depths of pie charts in 103 different languages.
In a first step I checked how the German and French case translate back to English. Theoretically, a flawless translation would go from "pie chart" to ? to "pie chart". This is called round-trip translation and considered a controversial quality metric for automated translation.
However, a literal translation would lose the original meaning and possibly expose different meanings. This is through limit of context - the translation engine makes a best effort picking out of multiple possibilities. While "camembert" translates back as "camembert", by adding more context translating "draw me a pie chart" translates to French as "me dessiner un camembert" and back identically. However, these literal translations due to lack of context are great for the purpose of this project.
To verify this briefly I translated the word to French and German - and back. Google Cloud Translation results in "Cake chart" and "Camembert". (The code for this is in the repository, function "de_fr_only".) As this worked out I went on to translate "pie chart" from English to 103 available languages, and back. The code is available here.
A note on limitations: I only receive one result per translation, languages could have several expressions for pie charts, I will only see one. Furthermore, the translations might simply be imperfect.
Results
Google cloud translation API supports 103 languages other than English. I wrote this program to translate "pie chart" to all of these languages and back.
The results are in the file all_the_pies.json, which is a JSON dictionary with two keys: "pie_to_foreign", and "foreign_to_pie". Each element contains a list "from" and "to", with the language indicator and the expression. This data structure is more verbose than required, a dictionary indexed by two-letter language code would have been sufficient for each. I did it this way as I wasn't sure what I want to do with the data later, and 103 languages are not all that much in the grand scheme of things.
When looking at the data, I noticed 74/103 of these are pie based, however, only 67 are "pie chart". Greek doubles the effort with "pie pie", Bengali has a "pie image", Portuguese is hedging bets with "pizza pie". Furthermore, "board pie": Haitian Creole, "graphic pie": Corsican, but most on-point is Afrikaans: "pie". 4/103 are cake based, however: 2x "diagram", 1x "chart" and 1x "table". I guess we could say that the pie chart takes the cake!
Other than cakes and pies or previously discussed examples, these 24 are different than the others.
card - Estonian
cart shape - Yoruba
chart chart - Kazakh
circular chart - Vietnamese
circular diagram - Bulgarian, Persian, Slovenian
circular graph - Croatian, Galician
diagram - Basque
drawing - Hausa
glassy table - Tajik
Graph of proportions - Romanian
Hidden chart - Pashto
organizer - Igbo
papa map - Maori
pastry photo - Azerbaijani
Pirate Chat - Sinhala
Point plan - Luxembourgish
skin - Samoan
table - Somali
table of the patient - Swahili
tablet - Hawaiian
the cookies - Hmong
Notably only "pastry photo" and "the cookies" are food based, all others are not related to food. I.e. 22/104 languages supported in Google Translate use an analogy not related to food for their expression of pie charts. While running this set me back 12 cents in cloud compute cost, I would argue that this insight was worth every penny!
Closing Thoughts
The majority of languages seems to relate pie charts to food, and within that mostly to pies. There are several notable exceptions that might seem obscure to English speakers. However, it remains an open question whether providing a proper name by Playwright for his creation 200 years ago would have lead to a less diverse naming situation for this chart. Maybe a good takeaway is to name inventions and systems straight away, as opposed to letting others name them.
As some might notice, this post lacks any actual pie charts. If you have been reading until here to see a pie chart, you have been tricked!
In this post we introduce Ex-Ray, our recently developed system. We use it to detect browser extensions which leak browsing history, regardless of their leakage channel. After analyzing Chrome extensions with more than 1,000 installations (10,691 total) we flagged 212 as leaking. We also found two extensions with large installation base that leak the users' history by means that were undetectable to prior work.
Our paper "Ex-Ray: Detection of History-Leaking Browser Extensions" is available for download here: pdf and bib. This project was a collaboration between Northeastern University and University College London. We will present the work at ACSAC this December.
The browser has become the primary interface for interactions with the Internet, from writing emails, to listening to music, to online banking. The shift of applications from the desktop to the Web has made the browser the de-facto operating system. Browser extensions can "extend" the core functionality of the browser, across all online activities of a user. They sometimes pave the way towards features which later become integrated into browsers themselves, such as password managers.
However, the access to powerful APIs given to extensions also allows for undesired side effects, such as invasion of privacy. This project is partially motivated by our previous analysis into the SimilarWeb browsing history data collection. We found 42 extensions that reported all of users' browsing history to a third party, often without it being required by the advertised functionality or disclosed in the terms of service.
This motivated us to investigate further and develop a more general detection system for privacy leaks in browser extensions. We wanted an approach that captures fundamental invariants of tracking browsing behavior that would be robust against obfuscation or encryption. Ex-Ray operates with two complementary systems in supervised and unsupervised fashion, and a triage system that would ease manual verification. We flagged 212 as history-leaking and discovered extensions that were leaking in ways that were out of scope for prior work. One extension was using strong encryption on tracking beacons before transfer, and the other one was using WebSockets. As our system works independently of the way of leaking, we were able to flag both.
Honeypot Probe
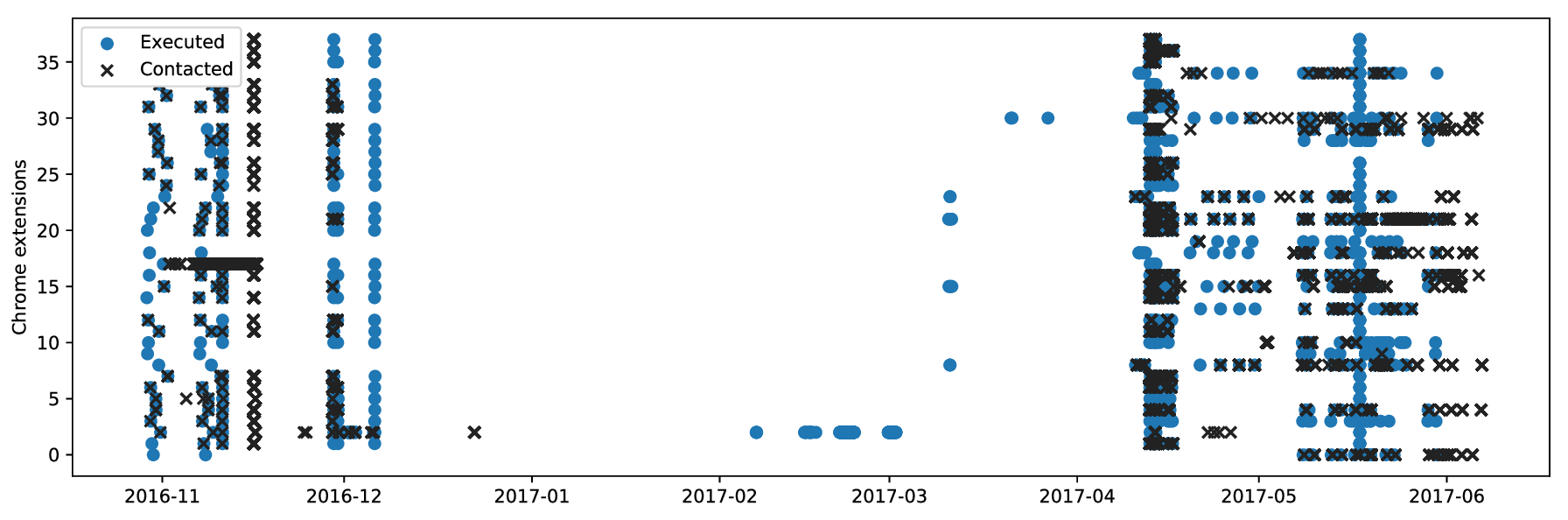
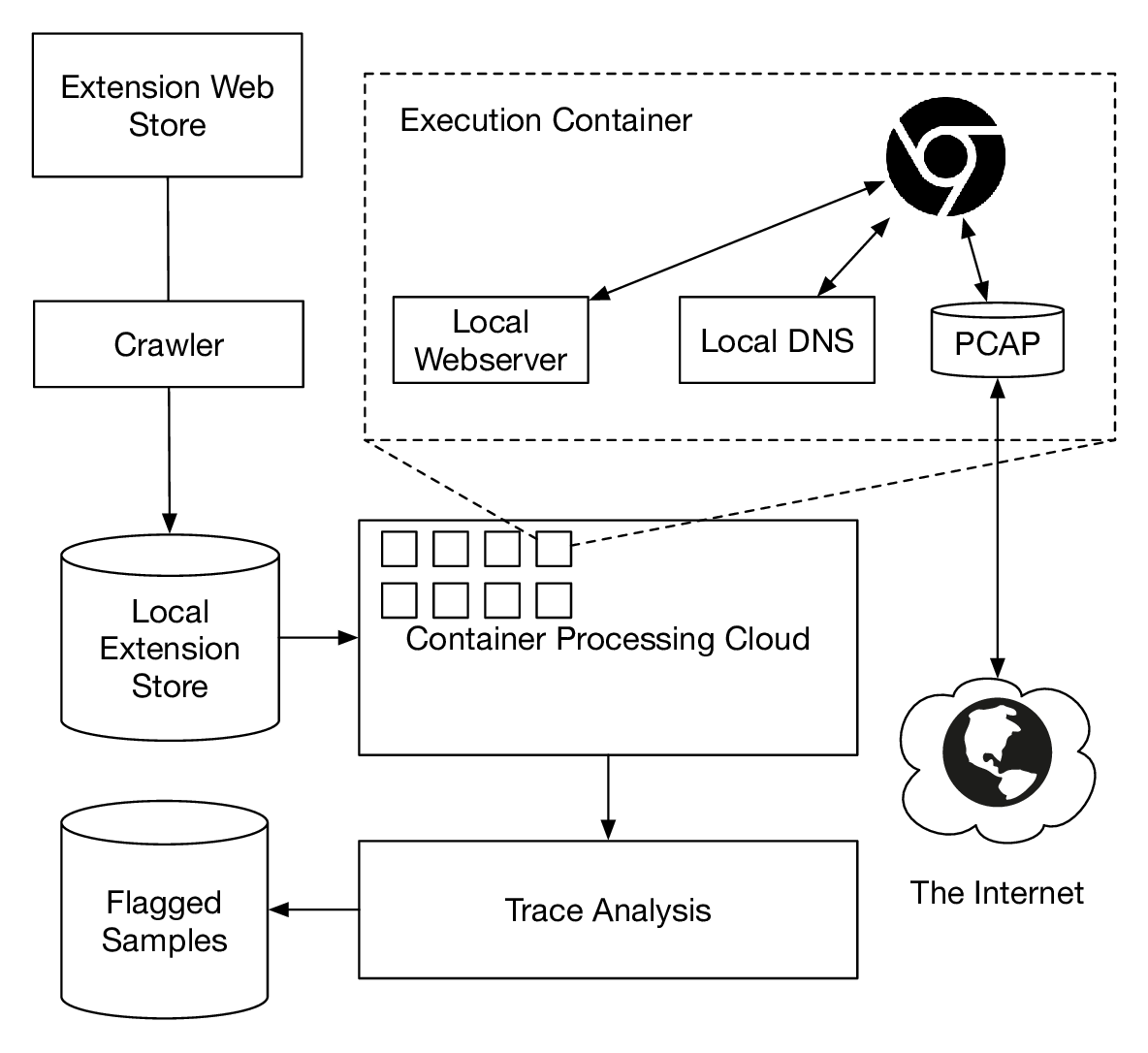
To gain insight into the environment in which trackers operate, and how data might be used, we configured a honeypot. We exercised extensions in a container and browsed by serving sites locally. Both Web and DNS were configured to work without interacting with the public Internet, except if extensions purposefully did so. We also operated a webserver with the same address on the public Internet that would collect incoming requests. As we encoded the extension ID into the URLs we visited, we were able to link incoming requests to extensions that have leaked them. After excluding VPN and proxy extensions, we found 38 extensions that would connect back to our honeypot. The confirmation that trackers are acting on leaked data motivated further steps in this work. We used these extensions as part of our ground truth for further experiments.
Here we compare extension execution to incoming request over time. We noticed that leaked history is often used immediately after it leaks to crawl the sites. These connections confirm that leaked browsing history is used by the receivers and is not leaked purely coincidentally. However, we identified no malicious behavior in our log files, such as vulnerability scans.
ABC ad blocking China special edition [translated]
CTRL-ALT-DEL new tab
Desprotetor de Links
Pop up blocker for Chrome
Similar Sites
nat-service.aws.kontera.com
Chistodeti
Woopages
199.175.48.183
static.36.51.9.176.clients.your-server.de
Other than the behavior over time, another aspect is possible collaboration between extension authors. In our honeypot probe we observed hosts that connected to multiple URLs unique to extensions, and conversely URLs that received connections from multiple hosts. These relations are possible indicators for a form of data sharing or shared infrastructure between trackers. Each line in this table consists of such a connected group.
System Description
Our system has three main components.
Unsupervised learning: based on counterfactual analysis on network traffic over multiple executions, we detect history-stealing extensions.
Triage-based analysis: A scoring system that can highlight extensions which have suspicious traffic behavior. It can be used as a pre-processing step to manually vet extensions.
Supervised learning: Using a labeled dataset from previous experiments, we can systematize identification of suspicious extensions. We build a model that detects leaks based on APIÂ calls.
In this post we will focus on the unsupervised learning component, for the other components we refer to the paper.
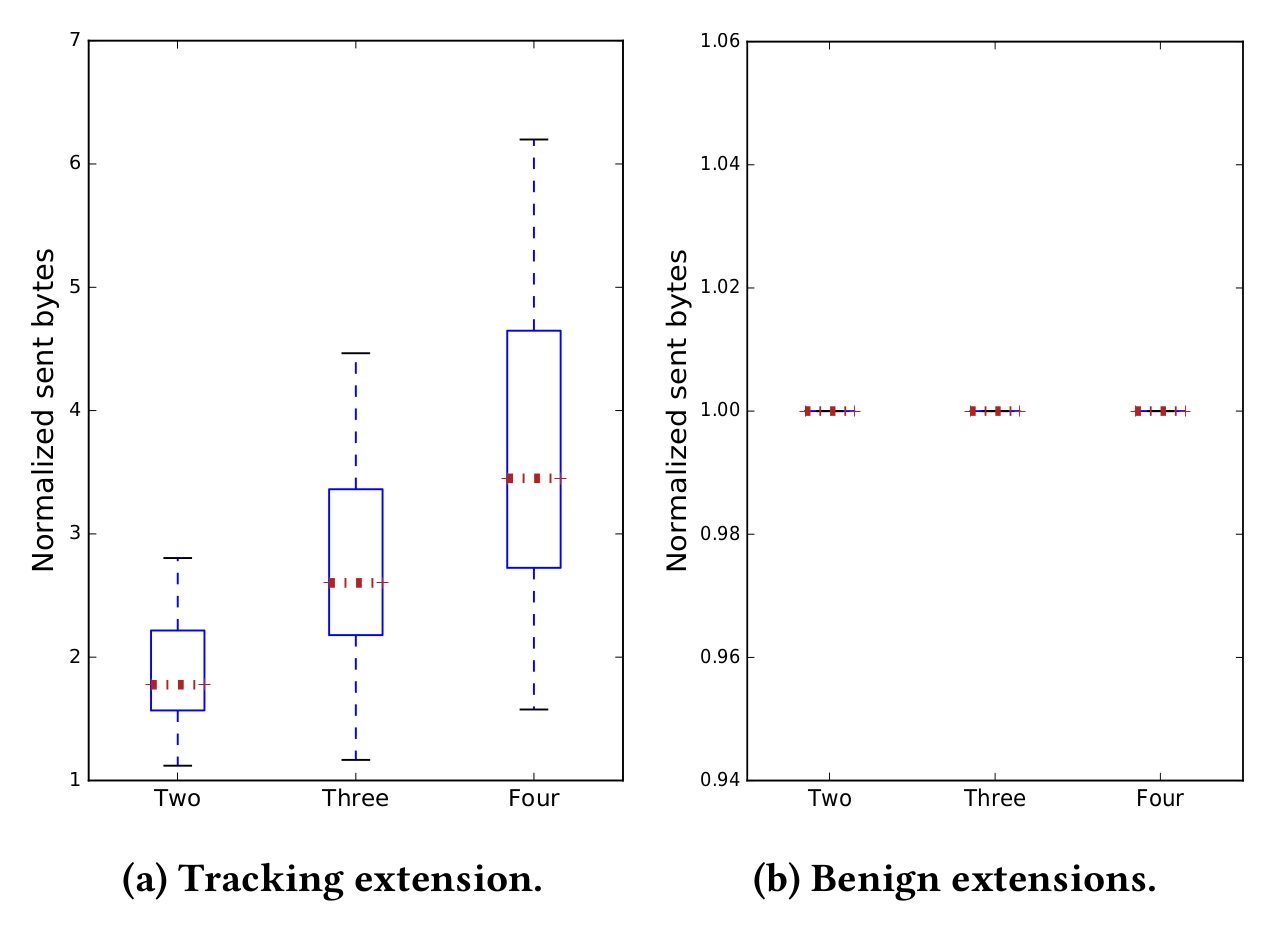
Comparison of sent traffic over several execution stages with increasing amount of history. On the Left we see history-leaking extensions, and on the right benign ones. Data that is sent out by extensions varies little for benign extensions, but for trackers it will vary depending on the amount of history supplied.
To identify privacy-violating extensions, we exercise them in multiple stages, changing the amount of private data supplied to the browser, and in turn to the extension under test. Based on the type of extension, the traffic usage can change depending on the number of visited sites. However, the underlying assumption is that benign extension traffic should not be influenced by the size of the browsing history.
Based on this insight, We use linear regression on each set of flows to estimate the optimal set of parameters that support the identification of history-leaking extensions. We aim to establish a causality relation between two variables: (i) the amount of raw data sent through the network and (ii) the amount of history leaked to a given domain. For this, we rely on the counterfactual analysis model. We use the size of history we provide to an extension as input variable to a controlled environment. Next, we observe outgoing traffic as an output variable for our classification. We also use other indicators such as lower bound of compressed history as cut-off value. The details of our detection engine are described in detail in the full paper (see links at top and bottom of post).
Ex-Ray extension execution overview. After downloading extensions from the Chrome Web Store, we exercise them in containers to collect traces for classification. To support our honeypot experiment we only access Web and DNS locally. As the subdomains we use are unique per extension and we keep the connections local to a container, leaks can be linked to the extension under test.
Results
In total, Ex-Ray flagged 212 Chrome extensions as history-leaking. This included two extensions which were undetectable to prior work. Web of Trust uses strong encryption (RC4) on extension level, before transfering data via HTTPS. Coupon Mate is an extension that leaks browsing history via WebSockets, which is used by 0.96% of extensions that we analyzed. Prior work uses keyword analysis on particular protocols, which would not have triggered on these two extensions.
Our dataset of flagged extensions and a triage report are available in our repository.
The amount of extensions leaking history is troublesome, in particular as this is possible for extensions with only modest permission access. While tracking on websites is prevalent, websites have to opt-in for it and solutions exist that allow users to remove them (e.g., Ghostery). Conversely, tracking in browser extensions covers all visited websites and no opt-out mechanism exists. This behavior does not seem to be monitored for in extension stores.
Takeaways
Our key takeaways from this project are as follows:
It is easy for a browser extension to monitor and report browsing to a third party without requesting suspicious permissions.
Extensions utilize leaking channels that have not been considered by state-of-the-art leak detection before.
Leaking behavior can be detected in a robust way with a combination of supervised and unsupervised methods, for example with a system such as Ex-Ray
Extension stores should monitor for such behavior and alert users of history leaks.
As a general precaution, users should be careful when installing browser extensions, as stores do not monitor for such behavior currently.
Conclusion
We introduce a new method for detection of privacy-violating browser extensions, independently of their protocol, and developed a prototype system: Ex-Ray. Our system uses a combination of supervised and unsupervised methods to identify features characteristic to leaking extensions. We analyzed all extensions from the Chrome Web store with more than 1,000 installations (10,691 total) and flagged 212 extensions as history-leaking. Two extensions that we flagged were leaking history in previously undetectable ways. We suggest that extensions should be both tested more rigorously when admitted to the store, as well as monitored while they execute within browsers. Our paper is available for download here: ( pdf and bib ).
This post describes a system we developed recently to re-introduce humans to automated vulnerability discovery. While human experts can find bugs unreachable to automated bug finding, we were curious whether untrained humans can help automated systems to do better. We found that by integrating human labor with no prior experience in bug finding, otherwise automated systems can overcome some of their shortcomings and find more bugs than they could on their own. We were able to recruit 183 workers through Amazon Mechanical Turk who helped increase program coverage. In effect this lead to a 55% improvement in finding bugs for Cyber Grand Challenge (CGC) binaries. This blog post will discuss key insights and material that did not fit into our forthcoming CCS paper (pdf and bib) "Rise of the HaCRS". The paper was a collaboration between UC Santa Barbara, Arizona State University, and Northeastern University.
Update: additional materials (slides, video) available here.
Introduction
Mechanical Phish is an open source Cyber Reasoning System (CRS) that scored third in last year's CGC event. CGC was a fully automated hacking competition with no human interaction, the first computer vs. computer hacking contest. While this pushed forward automated reasoning, it also highlighted shortcomings in the state of the art of automated bug finding. In this project we enhance fully automated bug finding by adding human assistance to cover areas where human intuition beats computing power.
A shortcoming of fully automated analyses is that tools start without real input and have to explore programs on their own. While lacking intuition, these tools can still fare well, for example AFL can reconstruct JPG file format on it's own, which is impressive. But we were curious whether better input seeds help automated reasoning and found through experimentation that we were able to enhance results significantly. In particular human intuition allows to distinguish states that are logically different, e.g.: winning a game as opposed to losing a game. While automated systems might be able to differentiate, the implications are not clear. Or more generally: semantic hints given by programs go unnoticed by a CRS.
We developed a prototype system which we tested on Amazon Mechanical Turk, evaluating against the CGC sample binary corpus. The results back our suspicion that new inputs can improve CRS findings significantly.
Mechanical Turk
Amazon offers access to human assistants where requesters can offer tasks to be solved for money. This service is often used to gather data where automation is infeasible or results must come from a human (e.g.: surveys). While our system is not designed specifically for Mechanical Turk, we chose the platform due to it's vast access to workers. In HaCRS, a "Tasklet" is a request for human work to solve an issue the CRS can't deal with on it's own. We issue these in steps. E.g., to improve coverage to a specific target, and once that's done we aim higher.
We armed our system with Amazon credits and iteratively let it issue HITs, requesting labor to increase coverage, such that Mechanical Phish can find more bugs. We had the system generally request coverage increases of 10%, and scale the payout based on difficulty. For example while a tasklet we thought of as easy would earn $1, a particularly hard one would be worth $2.5. Performance was measured in triggered program transitions, we provided live feedback as the Turkers were exercising the programs (see screenshots below). We further issued bonus payments based on performance that went further than required, so Turkers would be encouraged to exercise programs further. In total we paid $1,100 in base payment and bonuses to 183 Turkers.
HaCRS User Interface: The Human-Automation Link (HAL)
As we were hoping to enroll large amounts of unskilled labor in our experiments, the UI had to be self-explanatory to scale. Issues with the UI would result in confused emails and result in loss of time on both ends. We tried to fit all information the Turkers could need, and offer all options that could make them work faster.
Mechanical Turk does not allow for Turkers to install software for tasks. This is for good reason as requesters could exploit this to let them install malware or other unwanted software. However, this also presented a challenge for us: our interface needed to be accessible to them while observing this restriction. We decided to build a Web UI for our system, adding a noVNC JavaScript window where we presented the interaction terminal. This choice also lets us be flexible in the future, we can reuse most of the UI while pointing noVNC to other targets.
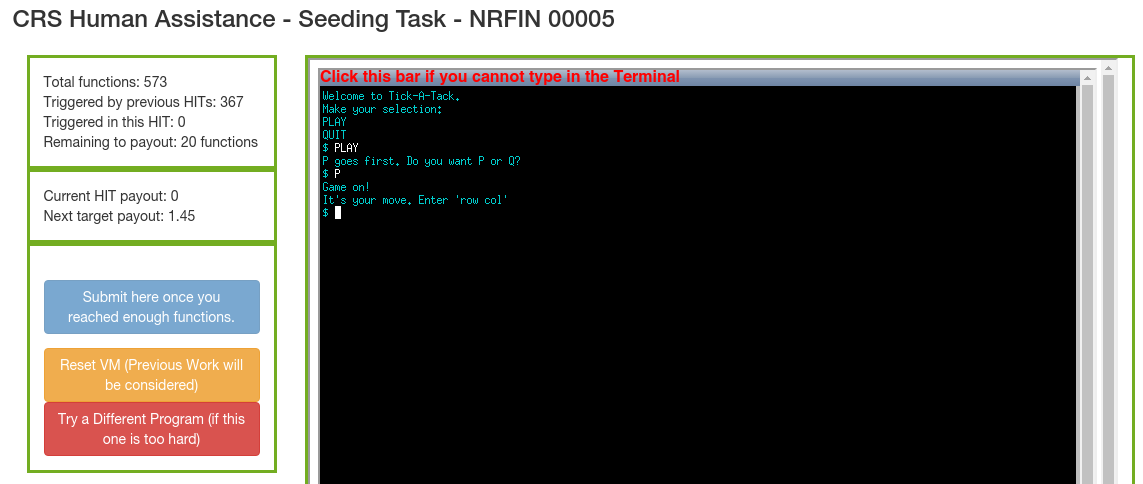
Above we see the HaCRS Human-Automation Link (HAL). Turkers can type in the terminal to interact with the program. To the left is the progress window. We see how many transitions have been triggered and how many more need to be triggered to receive a payout.
Turkers see previous input / output sequences and can restore these states by clicking on the character in the interaction. All inputs are available to all Turkers. I.e.: if any Turker manages to reach a previously unknown program state, they can pick up from there and explore further without manually repeating all steps. A click will spawn a new docker container in the backend, replay the interaction, and be available to the Turker via noVNC. Note that such replay is only possible for systems where randomness is controlled, this is a general limitation and not specific to HaCRS.
We also offer programmatic input suggestions based on strings that might be encountered later, which the Mechanical Phish otherwise lacks program context to use directly. These strings can function as inspiration to humans to exercise the program better.
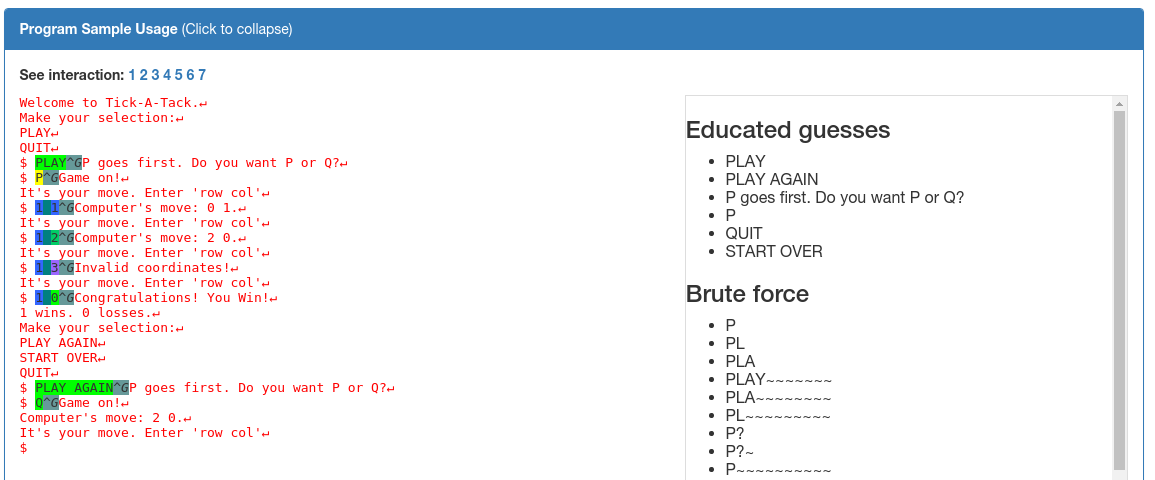
Sample program: NRFIN_00005
We will demonstrate HaCRS capabilities based on NRFIN_00005. This application is a game described as "Tic-Tac-Toe, with a few modifications". The player does not see the game board and has to keep track of state on their own. See screenshots above for gameplay and sample inputs. The game has a null pointer dereference bug, which can be triggered after one round has been played and typing "START OVER". Other strings will not trigger the vulnerability.
Driller and AFL (the two main components of Mechanical Phish) were not able to play the game successfully, as they cannot reason about the state of the game. Our Turkers however were able to win the game easily, but typed strings such as "PLAY AGAIN" afterwards, which does not trigger the bug. Next, Mechanical Phish picks up the Turker input and mutates it towards "START OVER", as it recognizes this as a special state, and crashes the program.
Takeaways
Our key takeaways from this project are as follows:
Input seeds can impact CRS results significantly, and should be used in conjunction with symbolic execution and fuzzing.
Even unskilled users' intuition can improve CRS results.
Mechanical Turk turned out to be a good platform for collecting diverse program interactions.
Semi-experts did not fare significantly better than non-expert users. However, this could be a limitation of our system.
Future Work
For HaCRS, we used humans to increase program coverage to reach states which Mechanical Phish could turn into crashes. However, we envision to involve humans in other areas to enhance CRSs. For example enroll them more directly into exploit generation, or testing patches to verify fixes. These tasks might be less suitable for unskilled labor, and will require more research. Furthermore, finding optimal incentive structures could increase performance of such systems.
Conclusion
We had a total of 183 Turkers work for us at a combined cost of $1,100. These Turkers managed to help Mechanical Phish find 55% more bugs than it could on it's own. HaCRS presents a step towards augmenting traditional CRSs with human intuition where computers are still lacking. Such a combined approach should be further explored to overcome CRS obstacles. Our paper features case studies and implementation details about our system. The full paper is available here: pdf and bib, and will be presented at CCS in Dallas.
This post investigates the upalytics.com library for Chrome extensions performing real time tracking of users on all sites they visit. The code is bundled with plenty of "free" extensions, exfiltrating browsing history as a feature. Such software is commonly known as spyware. Within the top 7,000 extensions of the Chrome Web store, the library is used 42 times with over 8 million installs. The post also looks into the relationship of upalytics with similarweb.com. The compiled data is also available in this spreadsheet.
Update: We published a paper about a system to automatically find such extensions.
Intro
I came across a website that offered browsing insights for websites they have no clear relation to, similarweb. The data includes links clicked on a site, referrer statistics, the origin of users, and others. While this is interesting, it also raises a question - where is that data coming from? Based on their website they collect data from millions of devices, but the software they advertise was orders of magnitude away from that. Data had to come from somewhere else.
Bundling unwanted content with "free" software is an unfortunate reality which has been shownbefore. This quickly became my working theory. Tracking browsing behavior alone is nothing new, but I was surprised by how widespread this library turned out to be.
Methodology
I started with the similarweb Chrome Extension, this is where I first came across the upalytics library. By doing some code reading I noticed it was tracking browsing habits and reporting it in real time. Next I started looking for similarities between this extension and the 7,000 most popular ones offered in the Chrome Web store.
Step one was an educated grep - looking for the "upalytics" string, which led to the first hits. What these libraries had in common is the string "SIMPLE_LB_URL" when accessing the backend API. Searching for that lead to more results, not all libraries contain the "upalytics" string.
To evaluate these extensions I wanted to know:
Does installing the extension exfiltrate data?
Does tracking happen out of the box, or does the user have to opt-in?
Is this mentioned in the terms of service?
If not, is there at least a link in the terms of service that explains what is happening?
I changed the endpoint address in each extension to point towards my server and evaluated each extension.
Results
I found 42 extensions which used the library totaling 8M installs. Note: "Facebook Video Downloader" (1,000 installs) required updating of the manifest to install.
Containing the code alone does not imply an extension exfiltrates data. But, manual testing confirmed: every single one was tracking browsing behavior. With every requested site, the extensions will send another POST request in the background to announce the action. What is particularly problematic is that some of these extensions pretend to be security relevant. Including phishing protection or content filters.
Out of these 42 extensions 23 did not mention data collection in their terms, out of these 12 further have no URL where this would be explained. One URL that is used across 12 extensions to explain the privacy ramifications is http://addons-privacy.com. The only extension offering opt-in to tracking is "SpeakIt!". They had an issue opened here where someone pointed this out as spyware before introduction of the opt-in step.
All data is compiled into a spreadsheet, available here.
Noteworthy examples
Do it - a Shia LaBeouf motivator: In exchange for browsing history users can get motivated by Shia. The extension offers a button that will make him pop up and shout a motivational quote. 200 thousand users considered this a good deal, who am I to judge? :-)
Video AdBlock for Chrome - this extension is advertised as "ADWARE FREE We are not injecting any third-party ads!". Technically this might be correct. Is spyware and adware the same?
Taking a peek
To see what is transmitted I modified the phishing extension (and all others) to post data to my local server instead of theirs. This was fairly simple - I set up a python Flask application that accepts POST requests to /related and GET requests to /settings. The POST data is base64 encoded - twice. Why twice? I don't know. Below is the data the server-side sees while the client is browsing. Line breaks inserted to help readability.
# We go to bing, after previously visiting asdf.com:
s=714&md=21&pid=gvOq01lLa3ZBt6z&sess=475474837468937000&q=http://www.bing.com/
&prev=http://asdf.com/&link=0&sub=chrome&hreferer=&tmv=3015
# We send a query "this is a test":
s=714&md=21&pid=gvOq01lLa3ZBt6z&sess=475474837468937000&q=http://www.bing.com/search?
q=this+is+a+test&go=Submit&qs=n&form=QBLH&pq=this+is+a+test&sc=8-14&sp=-1&sk=&
cvid=456B43655F44452BB33CC9AE204294B3&prev=http://www.bing.com/&link=1&
sub=chrome&hreferer=http://www.bing.com/&tmv=3015
# We click a link on the bing results:
s=714&md=21&pid=gvOq01lLa3ZBt6z&sess=475474837468937000&q=https://en.wikipedia.org/wiki/This_Is_Not_a_Test!&
prev=http://www.bing.com/search?q=this+is+a+test&go=Submit&qs=n&form=QBLH&pq=this+is+a+test&sc=8-14
&sp=-1&sk=&cvid=456B43655F44452BB33CC9AE204294B3&link=1&sub=chrome&hreferer=http://www.bing.com/search?q=this+is+a+test
&go=Submit&qs=n&form=QBLH&pq=this+is+a+test&sc=8-14&sp=-1&sk=&cvid=456B43655F44452BB33CC9AE204294B3&tmv=3015
What data will be transmitted?
Every visited website
Search queries (Google, Bing, etc. )
Websites visited on internal networks
As far as I can tell this will not be transmitted:
POST data (e.g.: passwords, usually)
Keypresses
The network view
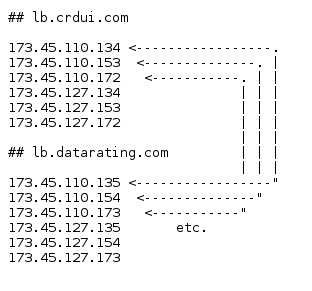
The endpoints that receive the data use a variety of domain names with multiple IPs. These 42 extension use nine distinct domains, eight of which use the same subdomain (lb.domain.com), one is a subdomain of upalytics.com. I suspect an attempt to distract from the impression that all data flows to one company. The domain names include ones that are supposed to look benign, connectupdate.com, secureweb24.net, searchelper.com. The other domains involved are: crdui.com, datarating.com, similarsites.com, thetrafficstat.net, webovernet.com.
All these domains are registered with domainsbyproxy, a service used to obscure the ownership of domain names. This includes upalytics.com itself which is used in one of the extensions (Speakit!). Also, the robots.txt file used in all cases is the same.
What's more interesting: All these IPs belong to the same hoster, XLHost.com. Eight out of nine of these hosts have all addresses in a /18 network, half of the IPs of the upalytics.com endpoint are in another xlhost network. For browsing convenience (or your firewall?) the list of IPs is available here. All IPs in use are unique, however, this involves consecutive IP addresses and other neighborhood relationships.
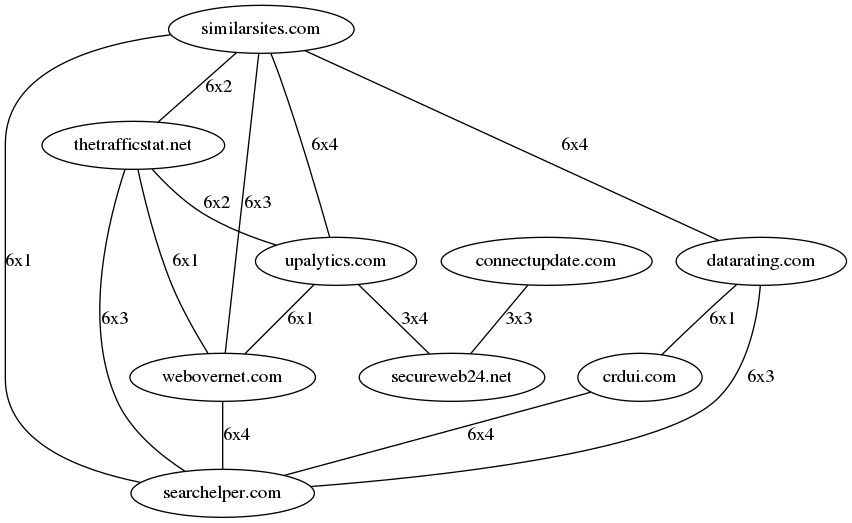
To examine this closer I compared the distance of IP addresses used by these extensions for tracking. In the graph below, the nodes are the nine domain names in use, edges are amount x distance. By taking into account distances of up to four, we can link together all hostnames used in all 42 extensions. For example: IPs "1.1.1.1" and "1.1.1.3" have a distance of 2. As for the labels, the edge between "similarsites.com" and "thetrafficstat.net" reads "6x2". This means that the domains share 6 IP addresses with a distance of 2. Before the graph, this is the relationship between lb.crdui.com and lb.datarating.com:
Combining all hosts into one graph, we get this:
What does this imply? Whether this is one large data kraken or pure coincidence, I will leave for the reader to decide.
Is this malware, an unwanted feature, or totally OK?
Some of these extensions have terms that mention privacy, here is an example:
We consider that the global measuring and ranking of the Internet in the current market is somewhat underdeveloped and obscure. For this reason, we have undertaken a large global project which bring a powerful improvement in the public’s perception of internet trends and expand the overall comprehension of the dynamics that are happening on the internet on daily basis. In order to make this goal a reality, we need anonymous data such as browsing patterns, statistics and information on how our features are being used. When installing one of our free products, you will expect to become a proud part of this project and make this change happen together with us. If you want more details on the interaction that will be going on between your browser and our servers, feel free to check out our Privacy Policy. By installing our product you adhere to the Terms and Conditions as well as Privacy Policy adhered on: http://crxmousetou.com/
Calling the data "anonymous" seems bold, an IP alone can often be used to uniquely identify users, let alone browsing history. Based on this text the majority of users might not be aware of the extent of monitoring. I was surprised myself by the boldness of the tracking. However, even if this was laid out clearly in the terms, common sense dictates that browser extensions have no business recording unrelated traffic.
That being said, this behavior could be in violation of the Extension Quality Guidelines, in particular the "single purpose" rule. Whether this is the case, I can not judge.
Limitations
This post looks into usage of this one library in the Chrome Extensions in the Chrome Web store alone. The number of extensions I found is to be considered as a lower bound, there could be well more. For the extensions I examined I did not check other libraries that were loaded or checked for behavior other than tracking browsing history. Upalytics also offers libraries for other platforms (Smartphones, Desktop, other browsers) - I did not take a look at these either.
Closing
This is just one library for one platform. Uplaytics supports all major smartphones, browsers but also Microsoft and Mac platforms. Also, there are more players in the game than this one.
I'm afraid to say that even if all these extensions get nuked from the store, there might be plenty similar libraries in other extensions.
Updates
04/01/16: None of these extensions are accessible in Google Web store at this point.
03/31/16: I expanded on the explanation of the IP relationships.
10/05/17: We published a paper to detect such leaks automatically. See here for details.
This post describes how to do function-level instrumentation of JavaScript programs using a Closure Compiler fork which is available here. The repository contains all code used here in the instrumentation-sample directory. Program points that can be hooked are function definition, invocation, and exit. Closure supports instrumentation internally as-is, this fork makes it more useful. Since Closure is already a popular part of JS build chains, it was an attractive target to add this feature to. I used this code as part of a project for JS hardening (ZigZag).
Update: The code has been merged into the official Closure repository.
instrumentation_template FILE is the new option. The specified file contains the code that will be added to the JS file.</p>
Code specified as `"init"` will be prepended to the program, this is where function definitions for the report call/exit/defined functions go. The other three types: report_call, report_exit and report_defined specifiy the functions that should be invoked for those actions. These functions are where one wants to fill in the blanks with one's own code to see what's happening in a program.
Here is a bare-bones instrumentation template:
`fun_id` is a unique identifier of functions within the program. The report_exit function will be used in a return statement. It is important to keep in mind that user specified function has to return the return argument (`return_value`), otherwise the instrumented program will not work as hoped for. When compiling a program that consists of one function:
# Accessing arguments
An example that is more interesting would be logging arguments used in a function call. For that, the arguments variable can be used. Since this variable is not defined in the script otherwise, it needs to be defined as an extern. The externs file contains only one line: "arguments". To instrument the program, the command line has to be extended by:
`--externs externs.txt --jscomp_off=externsValidation`
The updated code for the `"init"` section of the instrumentation template:
# Closing
This post explains how to use a modified version of Closure Compiler to instrument programs via templates. I found it a pity Closure doesn't allow for easier instrumentation out of the box, and hope this code can be useful to others working with JavaScript.