Query parameters in URLs are sometimes useful, but often they are not.
For example, shared Twitter links have additional tracking information that have no functional advantage when sharing.
They can be removed manually when sending a link to someone, but that time accumulates.
To automate this I created an iOS shortcut to remove them when a link is in the clipboard to reduce the privacy impact.
iOS Shortcuts
Shortcuts is an iOS app that allows to combine actions on iOS without having to create standalone iOS apps.
The interface is simple enough that it can be used from a phone while creating useful tools.
The API is powerful, even something as simple as links directly into iOS settings can be a time saver.
In previous iterations the application was known as Workflow, and since iOS 13 Shortcuts are available as app installed by default.
Implementation
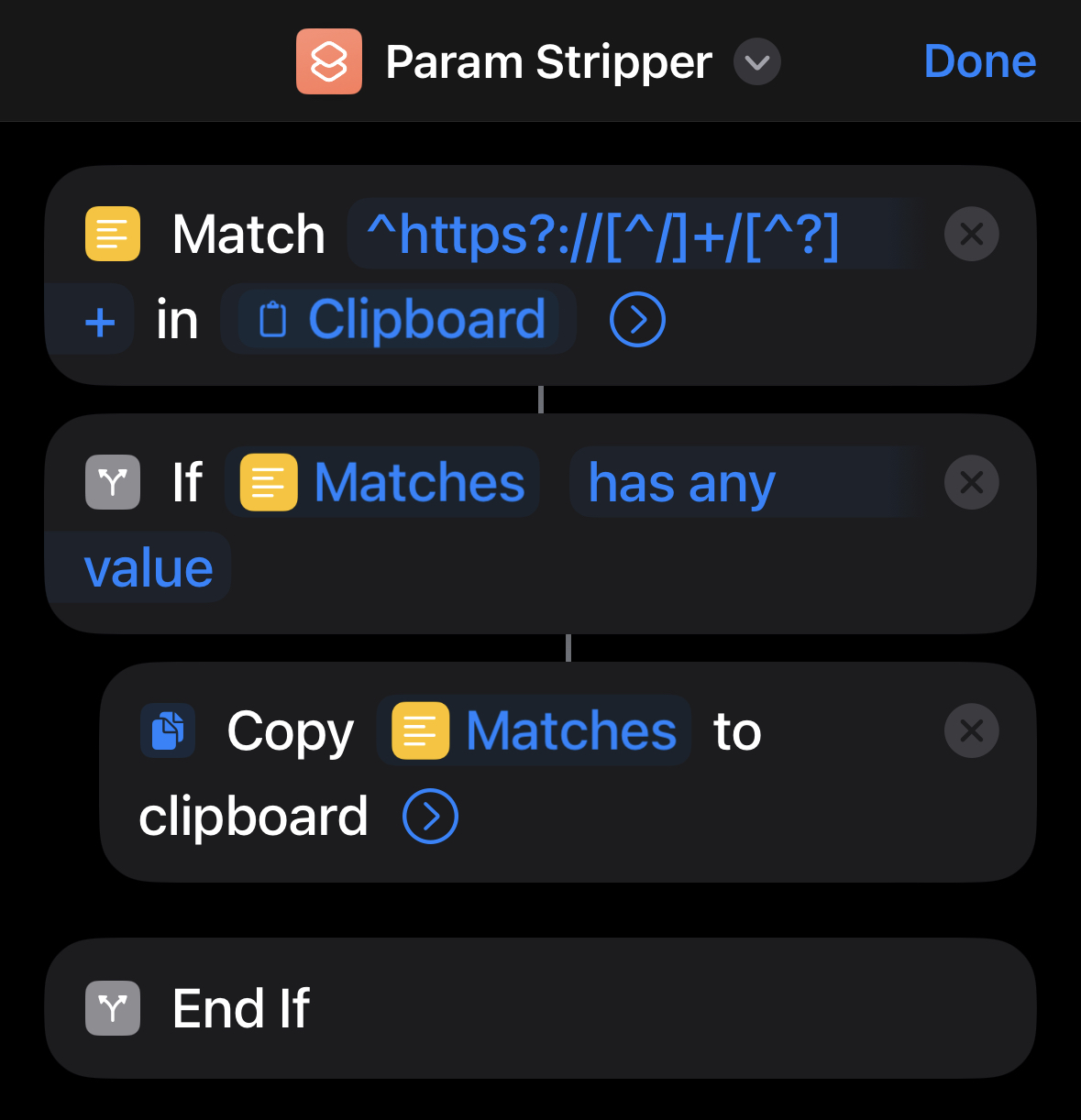
Links shared from Twitter have the following format:
In this case none of the query parameters serve a function other than tracking.
Treating the URL as a string stripping parameters is simple enough - keep everything before ? and discard the rest.
Conveniently iOS Shortcuts let us access the clipboard just like that, no parsing of the URL is necessary in this case.
For me this was the first time I used iOS shortcuts and I have to say that it is surprisingly easy to use.
We can pull data from the clipboard and apply regex directly to it, we match for content pre-question mark in URLs and write the match back to the clipboard - if any.
Since this URL pattern is not limited to Twitter I made the script remove all query parameters regardless of host.
Instagram, Amazon and others similarly use query parameters merely for tracking.
My shortcut is available here but it should be simple to reimplement manually.
Addendum
After putting this together I learned that iOS 17 will support such functionality natively, no shortcuts required.
This is a great feature and I’m glad it will arrive natively in iOS to boost user privacy a bit.
In 1892 an anonymous artist in Germany drew the now famous duck/rabbit optical illusion.
It was soon popularized by psychologists and even Ludwig Wittgenstein.
To one person it will be a duck and others a rabbit.
What people see first is tied to their expectations and other mental models.
This situation is not limited to humans, computers have similar difficulties in parsing input.
Parsers in programming languages similarly can read the same input but draw different conclusions about what to make of the data.
Go
Go is a widely popular language for backend programming and powers large chunks of the internet.
Go comes with fresh implementations of many parsers, yet allows to import code written in C which is often used to include older parsers to Go programs.
When it comes to picking a parser, developers make a choice picking one over the other.
This choice is not well understood, as these parsers can disagree on certain inputs leading to diverting behavior.
We were wondering whether these divergences can be leveraged for security and correctness testing, and developed a differential fuzzer to study such effects and identify vulnerabilities.
Fuzzing
For this project we developed a differential fuzzer that compares parsers implemented in Go natively vs. parsers imported via cgo.
We found that the choice whether to stay native or import is a hard one and hope to provide some guidance.
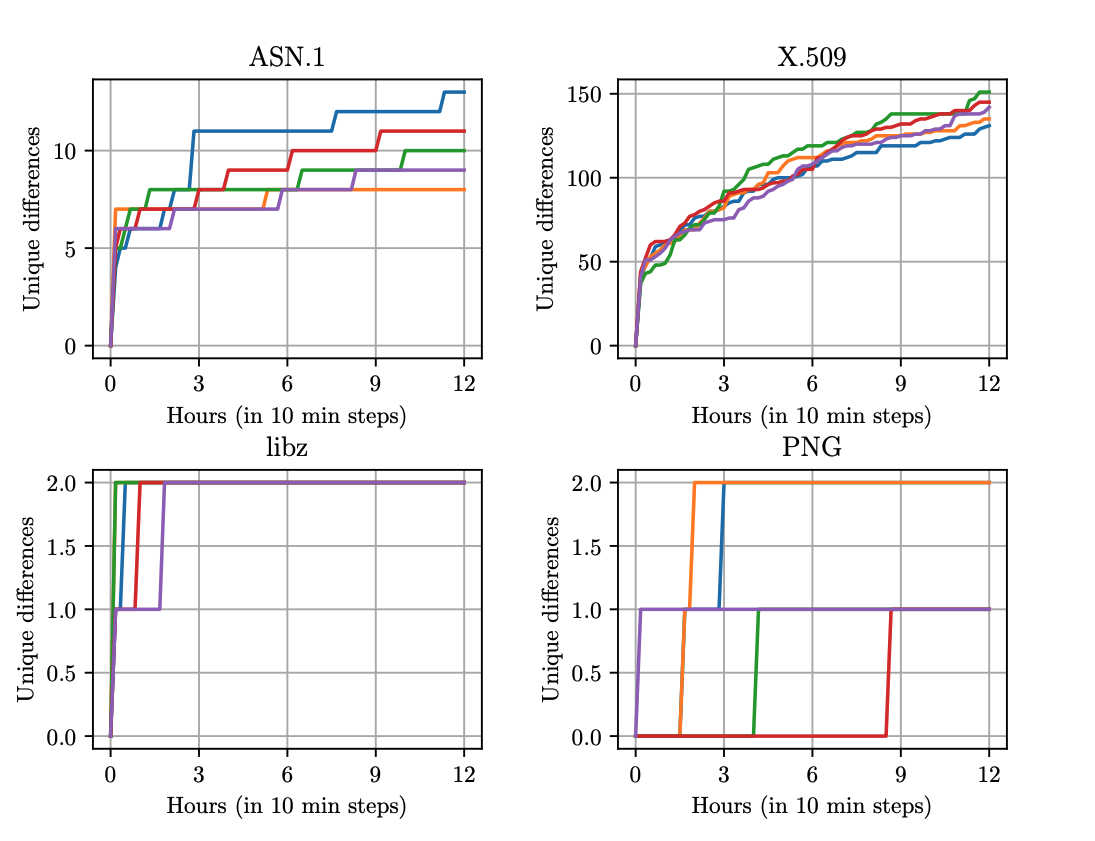
As targets we picked four popular libraries: libcrypto, libpng, libssl, and libz - we found differences in parsing that can be exploited which we line out in two case studies.
This work also resulted in a patch to Go compress/zlib.
GitHub package popularity
We also present an analysis of how prevalent unsafe, cgo, and assembly code are on popular GitHub repositories - they are more popular than we expected!
C code was present in 54% of repositories and unsafe in 29%, 23% of repositories used both.
Type
Repositories
Unsafe
298 (29.77%)
C
550 (54.95%)
S
51 (5.09%)
C+Unsafe
237 (23.68%)
C+S
48 (4.80%)
S+Unsafe
47 (4.70%)
C+S+Unsafe
45 (4.50%)
No C or Unsafe
390 (38.96%)
No C, S, or Unsafe
389 (38.86%)
All
1,001 (100%)
Paper
Our paper is available now and will be presented at WOOT’23.
This year WOOT is co-located with S&P in SF at the end of May.
I had the great opportunity to give a guest lecture at the Chalmers Security & Privacy Lab in Gothenburg, Sweden.
The talk was titled “Building a Secure Foundation”, more details here.
It was great to meet everyone!
I had the opportunity to work on a recent product launch at Block/Square in collaboration with Apple: Tap to Pay on iPhone, which became available recently!
The project brings accepting NFC payments directly to iPhones.
It was a lot of fun to work on the project and with such a great team.
More details and how to activate are available here.
An extended edition of our HotFuzz work (conference publication at NDSS) has been published in the ACM Transactions on Privacy and Security.
This paper provides significantly more detail on resource exhaustion vulnerability discovery, covers both temporal and spatial attacks and discusses more discovered vulnerabilities.
Paper available from ACM via open access here.
AWS Lambdas have recently been extended with a new feature that adds a runtime environment before a Lambda is executed: Lambda extesions.
We have published a writeup on the Square Developer blog how we trialed this technology before it was generally available to prefetch secrets from Secrets Manager: Using AWS Lambda Extensions to Accelerate AWS Secrets Manager Access.
This work has also been covered in the AWS Compute Blog.
HotFuzz is a project in which we search for Algorithmic Complexity (AC) vulnerabilities in Java programs. These are vulnerabilities that can significantly slow down a program to exhaust its resources with small input. To use an analogy - it is easy to overwhelm a pizza place by ordering 100 pizzas at once, but can you think of a single pizza that would grind the restaurant's gears and bring operation to a halt?
We created a specialized fuzzer that ran on a customized JVM collecting resource measurements to guide programs towards worst-case behavior. We found 132 AC vulnerabilities in 47 top maven libraries and 26 AC vulnerabilities in the JRE including one in java.math that was reported and fixed as CVE-2018-1517.
Effects of exploiting an AC vulnerability can be similar to a Denial of Service attack. However, these are often linear in behavior - the attacker sends lots of requests that overwhelm the target system. For this project we are interested in attacks where input and effect are disproportional. For example, making one request and causing a program to be stuck in a loop exhausting it's CPU. There is some related work such as SlowFuzz or PerfFuzz. However, we decided this topic needs further exploration.
System
As opposed to fuzzing a program's main entry point, we fuzz all methods treating them as potential entry points. To generate input values for method parameters we use Small Recursive Instantiation (SRI) based on type signature. We recursively instantiate objects which can be passed into the method invocation, for primitive variables we generate values randomly. However, since uniform distributions are not ideal for Java objects we use a custom distribution which is described in the paper. These form the initial population for our genetic algorithm where we use CPU utilization as fitness function driving towards worst-case consumption. This process emulates natural selection where entities in a population are paired and produce cross-over offspring with some mutations. Typically fuzzers do cross-over on bit level, extending this technique to objects with type hierarchies is a central component of micro-fuzzing.
As baseline to compare against we used another instantiation approach called Identity Value Instantiation (IVI). For example: 0 for integer, empty string for strings, etc. IVI is the simplest possible value selection strategy possible and merely used to assess effectiveness of SRI.
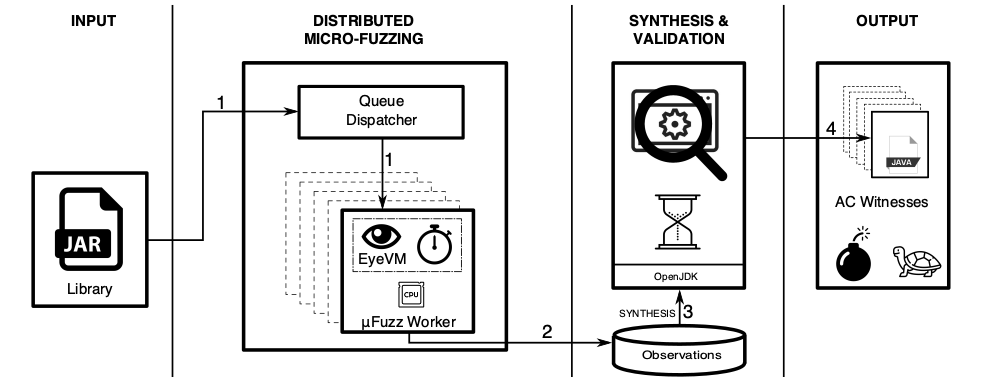
For measurement microFuzz workers contain a custom JVM that is called EyeVM. EyeVM is built on top of OpenJDK with a HotSpot VM modified for measuring precise CPU consumption.
Output from micro-fuzzing is passed on to witness synthesis and validation where a generated program is run and measured on an unmodified JVM. This verification step reduces false positives where fuzzing causes programs to hang, for example polling a socket or file. The synthesized program calls the target method with help from the reflection API and the Google GSON library, using wall-clock to measure runtime.
HotFuzz system overview leading from jar file to AC witnesses
Results
We micro-fuzzed the JRE, the top 100 maven repositories, and challenges provided to us by DARPA. We found 132 AC vulnerabilities in 47 top maven libraries and 26 AC vulnerabilities in the JRE including one in java.math.
One finding that resulted in a CVE that was fixed by Oracle and IBM in their JRE implementations is CVE-2018-1517. HotFuzz found input to BigDecimal.add, which is an arbitrary precision library, that would lead to dramatically slowed down processing. In the case of IBM J9 we measured the process to be stuck for months. The cause for the slow down lies in how variables are allocated in the library. The bug and more results are presented in detail in the paper.
Other than comparing SRI with IVI fuzzing, a negative result that is not covered in the paper is that we also tried seeding fuzzing input with data from unit tests of libraries. These have not resulted in improved fuzzing results which was a surprise to us.
Summary
HotFuzz is a method-based fuzzer for Java programs that tries to drive input towards worst-case behavior in regards to CPU consumption. We found bugs in popular maven libraries and one CVE in java.math that lead to fixes by Oracle and IBM. The paper will be published at NDSS this year.
In this post we introduce Ex-Ray, our recently developed system. We use it to detect browser extensions which leak browsing history, regardless of their leakage channel. After analyzing Chrome extensions with more than 1,000 installations (10,691 total) we flagged 212 as leaking. We also found two extensions with large installation base that leak the users' history by means that were undetectable to prior work.
Our paper "Ex-Ray: Detection of History-Leaking Browser Extensions" is available for download here: pdf and bib. This project was a collaboration between Northeastern University and University College London. We will present the work at ACSAC this December.
The browser has become the primary interface for interactions with the Internet, from writing emails, to listening to music, to online banking. The shift of applications from the desktop to the Web has made the browser the de-facto operating system. Browser extensions can "extend" the core functionality of the browser, across all online activities of a user. They sometimes pave the way towards features which later become integrated into browsers themselves, such as password managers.
However, the access to powerful APIs given to extensions also allows for undesired side effects, such as invasion of privacy. This project is partially motivated by our previous analysis into the SimilarWeb browsing history data collection. We found 42 extensions that reported all of users' browsing history to a third party, often without it being required by the advertised functionality or disclosed in the terms of service.
This motivated us to investigate further and develop a more general detection system for privacy leaks in browser extensions. We wanted an approach that captures fundamental invariants of tracking browsing behavior that would be robust against obfuscation or encryption. Ex-Ray operates with two complementary systems in supervised and unsupervised fashion, and a triage system that would ease manual verification. We flagged 212 as history-leaking and discovered extensions that were leaking in ways that were out of scope for prior work. One extension was using strong encryption on tracking beacons before transfer, and the other one was using WebSockets. As our system works independently of the way of leaking, we were able to flag both.
Honeypot Probe
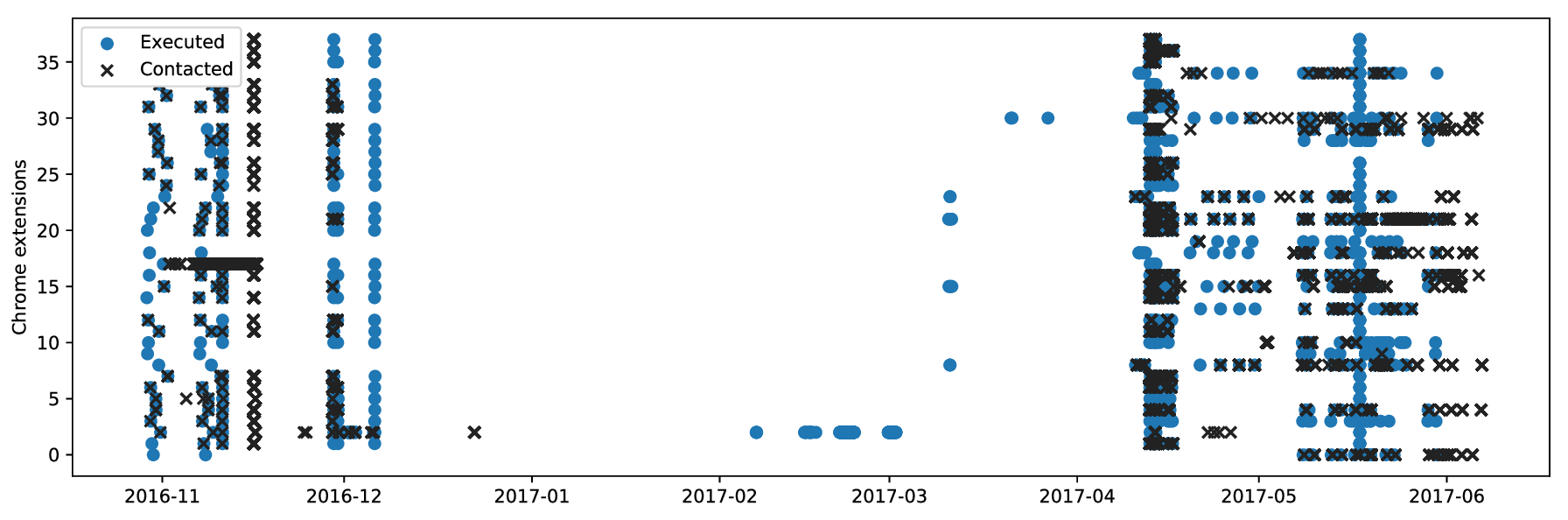
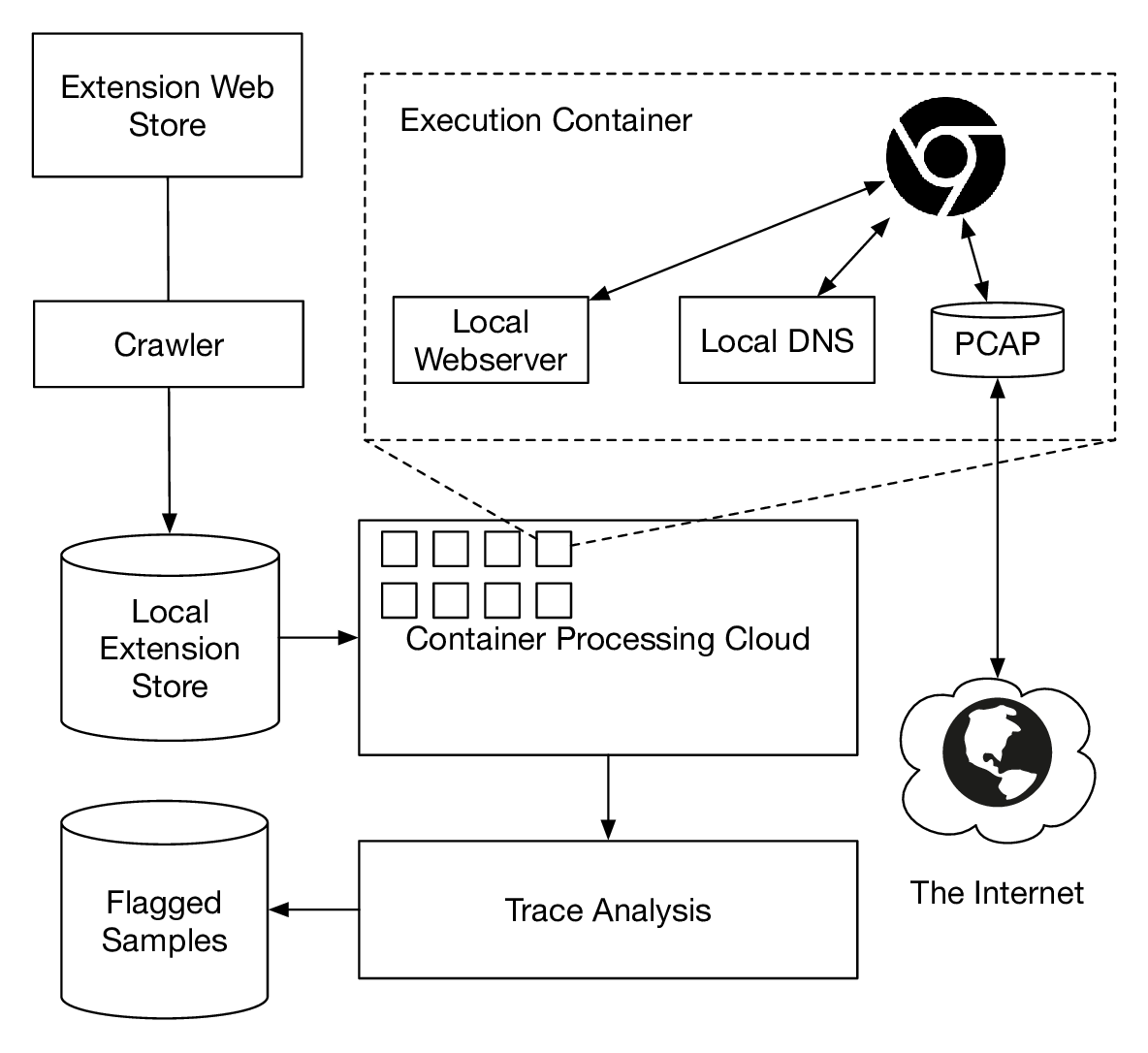
To gain insight into the environment in which trackers operate, and how data might be used, we configured a honeypot. We exercised extensions in a container and browsed by serving sites locally. Both Web and DNS were configured to work without interacting with the public Internet, except if extensions purposefully did so. We also operated a webserver with the same address on the public Internet that would collect incoming requests. As we encoded the extension ID into the URLs we visited, we were able to link incoming requests to extensions that have leaked them. After excluding VPN and proxy extensions, we found 38 extensions that would connect back to our honeypot. The confirmation that trackers are acting on leaked data motivated further steps in this work. We used these extensions as part of our ground truth for further experiments.
Here we compare extension execution to incoming request over time. We noticed that leaked history is often used immediately after it leaks to crawl the sites. These connections confirm that leaked browsing history is used by the receivers and is not leaked purely coincidentally. However, we identified no malicious behavior in our log files, such as vulnerability scans.
ABC ad blocking China special edition [translated]
CTRL-ALT-DEL new tab
Desprotetor de Links
Pop up blocker for Chrome
Similar Sites
nat-service.aws.kontera.com
Chistodeti
Woopages
199.175.48.183
static.36.51.9.176.clients.your-server.de
Other than the behavior over time, another aspect is possible collaboration between extension authors. In our honeypot probe we observed hosts that connected to multiple URLs unique to extensions, and conversely URLs that received connections from multiple hosts. These relations are possible indicators for a form of data sharing or shared infrastructure between trackers. Each line in this table consists of such a connected group.
System Description
Our system has three main components.
Unsupervised learning: based on counterfactual analysis on network traffic over multiple executions, we detect history-stealing extensions.
Triage-based analysis: A scoring system that can highlight extensions which have suspicious traffic behavior. It can be used as a pre-processing step to manually vet extensions.
Supervised learning: Using a labeled dataset from previous experiments, we can systematize identification of suspicious extensions. We build a model that detects leaks based on APIÂ calls.
In this post we will focus on the unsupervised learning component, for the other components we refer to the paper.
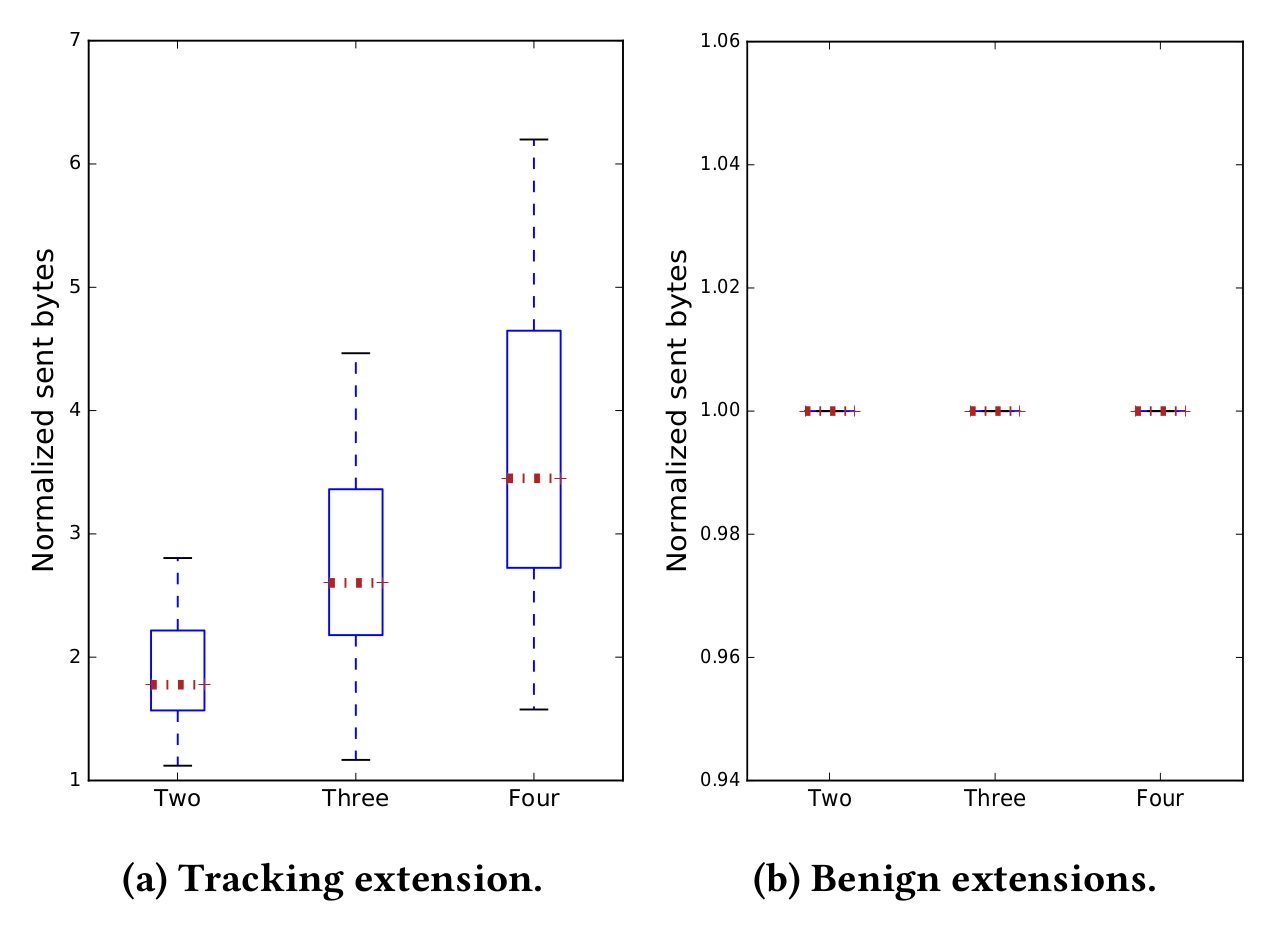
Comparison of sent traffic over several execution stages with increasing amount of history. On the Left we see history-leaking extensions, and on the right benign ones. Data that is sent out by extensions varies little for benign extensions, but for trackers it will vary depending on the amount of history supplied.
To identify privacy-violating extensions, we exercise them in multiple stages, changing the amount of private data supplied to the browser, and in turn to the extension under test. Based on the type of extension, the traffic usage can change depending on the number of visited sites. However, the underlying assumption is that benign extension traffic should not be influenced by the size of the browsing history.
Based on this insight, We use linear regression on each set of flows to estimate the optimal set of parameters that support the identification of history-leaking extensions. We aim to establish a causality relation between two variables: (i) the amount of raw data sent through the network and (ii) the amount of history leaked to a given domain. For this, we rely on the counterfactual analysis model. We use the size of history we provide to an extension as input variable to a controlled environment. Next, we observe outgoing traffic as an output variable for our classification. We also use other indicators such as lower bound of compressed history as cut-off value. The details of our detection engine are described in detail in the full paper (see links at top and bottom of post).
Ex-Ray extension execution overview. After downloading extensions from the Chrome Web Store, we exercise them in containers to collect traces for classification. To support our honeypot experiment we only access Web and DNS locally. As the subdomains we use are unique per extension and we keep the connections local to a container, leaks can be linked to the extension under test.
Results
In total, Ex-Ray flagged 212 Chrome extensions as history-leaking. This included two extensions which were undetectable to prior work. Web of Trust uses strong encryption (RC4) on extension level, before transfering data via HTTPS. Coupon Mate is an extension that leaks browsing history via WebSockets, which is used by 0.96% of extensions that we analyzed. Prior work uses keyword analysis on particular protocols, which would not have triggered on these two extensions.
Our dataset of flagged extensions and a triage report are available in our repository.
The amount of extensions leaking history is troublesome, in particular as this is possible for extensions with only modest permission access. While tracking on websites is prevalent, websites have to opt-in for it and solutions exist that allow users to remove them (e.g., Ghostery). Conversely, tracking in browser extensions covers all visited websites and no opt-out mechanism exists. This behavior does not seem to be monitored for in extension stores.
Takeaways
Our key takeaways from this project are as follows:
It is easy for a browser extension to monitor and report browsing to a third party without requesting suspicious permissions.
Extensions utilize leaking channels that have not been considered by state-of-the-art leak detection before.
Leaking behavior can be detected in a robust way with a combination of supervised and unsupervised methods, for example with a system such as Ex-Ray
Extension stores should monitor for such behavior and alert users of history leaks.
As a general precaution, users should be careful when installing browser extensions, as stores do not monitor for such behavior currently.
Conclusion
We introduce a new method for detection of privacy-violating browser extensions, independently of their protocol, and developed a prototype system: Ex-Ray. Our system uses a combination of supervised and unsupervised methods to identify features characteristic to leaking extensions. We analyzed all extensions from the Chrome Web store with more than 1,000 installations (10,691 total) and flagged 212 extensions as history-leaking. Two extensions that we flagged were leaking history in previously undetectable ways. We suggest that extensions should be both tested more rigorously when admitted to the store, as well as monitored while they execute within browsers. Our paper is available for download here: ( pdf and bib ).
This post describes a system we developed recently to re-introduce humans to automated vulnerability discovery. While human experts can find bugs unreachable to automated bug finding, we were curious whether untrained humans can help automated systems to do better. We found that by integrating human labor with no prior experience in bug finding, otherwise automated systems can overcome some of their shortcomings and find more bugs than they could on their own. We were able to recruit 183 workers through Amazon Mechanical Turk who helped increase program coverage. In effect this lead to a 55% improvement in finding bugs for Cyber Grand Challenge (CGC) binaries. This blog post will discuss key insights and material that did not fit into our forthcoming CCS paper (pdf and bib) "Rise of the HaCRS". The paper was a collaboration between UC Santa Barbara, Arizona State University, and Northeastern University.
Update: additional materials (slides, video) available here.
Introduction
Mechanical Phish is an open source Cyber Reasoning System (CRS) that scored third in last year's CGC event. CGC was a fully automated hacking competition with no human interaction, the first computer vs. computer hacking contest. While this pushed forward automated reasoning, it also highlighted shortcomings in the state of the art of automated bug finding. In this project we enhance fully automated bug finding by adding human assistance to cover areas where human intuition beats computing power.
A shortcoming of fully automated analyses is that tools start without real input and have to explore programs on their own. While lacking intuition, these tools can still fare well, for example AFL can reconstruct JPG file format on it's own, which is impressive. But we were curious whether better input seeds help automated reasoning and found through experimentation that we were able to enhance results significantly. In particular human intuition allows to distinguish states that are logically different, e.g.: winning a game as opposed to losing a game. While automated systems might be able to differentiate, the implications are not clear. Or more generally: semantic hints given by programs go unnoticed by a CRS.
We developed a prototype system which we tested on Amazon Mechanical Turk, evaluating against the CGC sample binary corpus. The results back our suspicion that new inputs can improve CRS findings significantly.
Mechanical Turk
Amazon offers access to human assistants where requesters can offer tasks to be solved for money. This service is often used to gather data where automation is infeasible or results must come from a human (e.g.: surveys). While our system is not designed specifically for Mechanical Turk, we chose the platform due to it's vast access to workers. In HaCRS, a "Tasklet" is a request for human work to solve an issue the CRS can't deal with on it's own. We issue these in steps. E.g., to improve coverage to a specific target, and once that's done we aim higher.
We armed our system with Amazon credits and iteratively let it issue HITs, requesting labor to increase coverage, such that Mechanical Phish can find more bugs. We had the system generally request coverage increases of 10%, and scale the payout based on difficulty. For example while a tasklet we thought of as easy would earn $1, a particularly hard one would be worth $2.5. Performance was measured in triggered program transitions, we provided live feedback as the Turkers were exercising the programs (see screenshots below). We further issued bonus payments based on performance that went further than required, so Turkers would be encouraged to exercise programs further. In total we paid $1,100 in base payment and bonuses to 183 Turkers.
HaCRS User Interface: The Human-Automation Link (HAL)
As we were hoping to enroll large amounts of unskilled labor in our experiments, the UI had to be self-explanatory to scale. Issues with the UI would result in confused emails and result in loss of time on both ends. We tried to fit all information the Turkers could need, and offer all options that could make them work faster.
Mechanical Turk does not allow for Turkers to install software for tasks. This is for good reason as requesters could exploit this to let them install malware or other unwanted software. However, this also presented a challenge for us: our interface needed to be accessible to them while observing this restriction. We decided to build a Web UI for our system, adding a noVNC JavaScript window where we presented the interaction terminal. This choice also lets us be flexible in the future, we can reuse most of the UI while pointing noVNC to other targets.
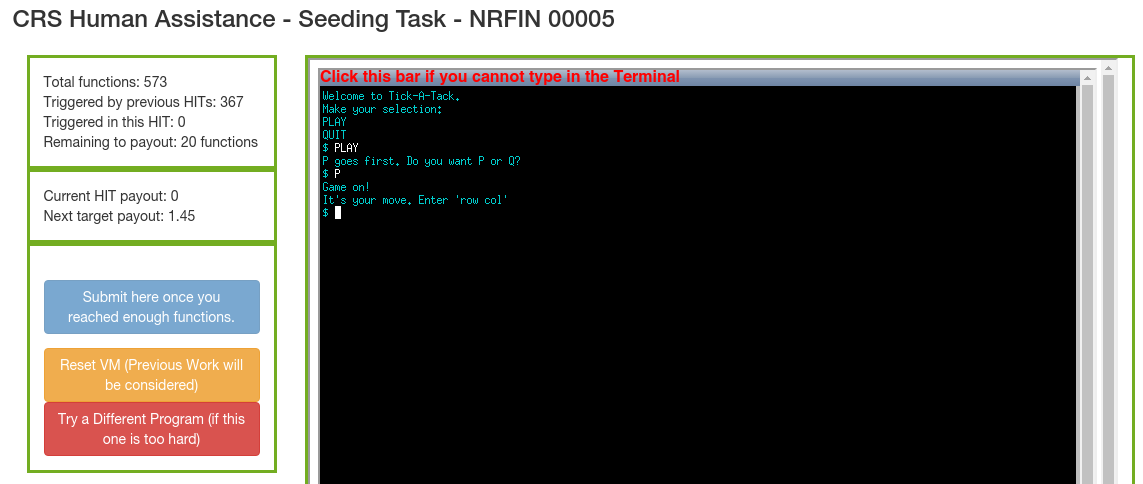
Above we see the HaCRS Human-Automation Link (HAL). Turkers can type in the terminal to interact with the program. To the left is the progress window. We see how many transitions have been triggered and how many more need to be triggered to receive a payout.
Turkers see previous input / output sequences and can restore these states by clicking on the character in the interaction. All inputs are available to all Turkers. I.e.: if any Turker manages to reach a previously unknown program state, they can pick up from there and explore further without manually repeating all steps. A click will spawn a new docker container in the backend, replay the interaction, and be available to the Turker via noVNC. Note that such replay is only possible for systems where randomness is controlled, this is a general limitation and not specific to HaCRS.
We also offer programmatic input suggestions based on strings that might be encountered later, which the Mechanical Phish otherwise lacks program context to use directly. These strings can function as inspiration to humans to exercise the program better.
Sample program: NRFIN_00005
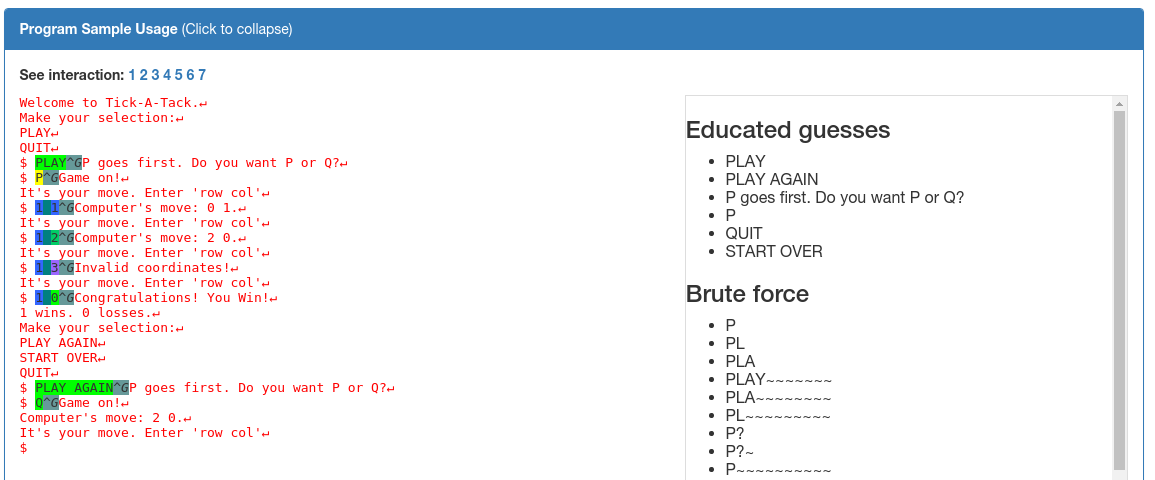
We will demonstrate HaCRS capabilities based on NRFIN_00005. This application is a game described as "Tic-Tac-Toe, with a few modifications". The player does not see the game board and has to keep track of state on their own. See screenshots above for gameplay and sample inputs. The game has a null pointer dereference bug, which can be triggered after one round has been played and typing "START OVER". Other strings will not trigger the vulnerability.
Driller and AFL (the two main components of Mechanical Phish) were not able to play the game successfully, as they cannot reason about the state of the game. Our Turkers however were able to win the game easily, but typed strings such as "PLAY AGAIN" afterwards, which does not trigger the bug. Next, Mechanical Phish picks up the Turker input and mutates it towards "START OVER", as it recognizes this as a special state, and crashes the program.
Takeaways
Our key takeaways from this project are as follows:
Input seeds can impact CRS results significantly, and should be used in conjunction with symbolic execution and fuzzing.
Even unskilled users' intuition can improve CRS results.
Mechanical Turk turned out to be a good platform for collecting diverse program interactions.
Semi-experts did not fare significantly better than non-expert users. However, this could be a limitation of our system.
Future Work
For HaCRS, we used humans to increase program coverage to reach states which Mechanical Phish could turn into crashes. However, we envision to involve humans in other areas to enhance CRSs. For example enroll them more directly into exploit generation, or testing patches to verify fixes. These tasks might be less suitable for unskilled labor, and will require more research. Furthermore, finding optimal incentive structures could increase performance of such systems.
Conclusion
We had a total of 183 Turkers work for us at a combined cost of $1,100. These Turkers managed to help Mechanical Phish find 55% more bugs than it could on it's own. HaCRS presents a step towards augmenting traditional CRSs with human intuition where computers are still lacking. Such a combined approach should be further explored to overcome CRS obstacles. Our paper features case studies and implementation details about our system. The full paper is available here: pdf and bib, and will be presented at CCS in Dallas.
This post investigates the upalytics.com library for Chrome extensions performing real time tracking of users on all sites they visit. The code is bundled with plenty of "free" extensions, exfiltrating browsing history as a feature. Such software is commonly known as spyware. Within the top 7,000 extensions of the Chrome Web store, the library is used 42 times with over 8 million installs. The post also looks into the relationship of upalytics with similarweb.com. The compiled data is also available in this spreadsheet.
Update: We published a paper about a system to automatically find such extensions.
Intro
I came across a website that offered browsing insights for websites they have no clear relation to, similarweb. The data includes links clicked on a site, referrer statistics, the origin of users, and others. While this is interesting, it also raises a question - where is that data coming from? Based on their website they collect data from millions of devices, but the software they advertise was orders of magnitude away from that. Data had to come from somewhere else.
Bundling unwanted content with "free" software is an unfortunate reality which has been shownbefore. This quickly became my working theory. Tracking browsing behavior alone is nothing new, but I was surprised by how widespread this library turned out to be.
Methodology
I started with the similarweb Chrome Extension, this is where I first came across the upalytics library. By doing some code reading I noticed it was tracking browsing habits and reporting it in real time. Next I started looking for similarities between this extension and the 7,000 most popular ones offered in the Chrome Web store.
Step one was an educated grep - looking for the "upalytics" string, which led to the first hits. What these libraries had in common is the string "SIMPLE_LB_URL" when accessing the backend API. Searching for that lead to more results, not all libraries contain the "upalytics" string.
To evaluate these extensions I wanted to know:
Does installing the extension exfiltrate data?
Does tracking happen out of the box, or does the user have to opt-in?
Is this mentioned in the terms of service?
If not, is there at least a link in the terms of service that explains what is happening?
I changed the endpoint address in each extension to point towards my server and evaluated each extension.
Results
I found 42 extensions which used the library totaling 8M installs. Note: "Facebook Video Downloader" (1,000 installs) required updating of the manifest to install.
Containing the code alone does not imply an extension exfiltrates data. But, manual testing confirmed: every single one was tracking browsing behavior. With every requested site, the extensions will send another POST request in the background to announce the action. What is particularly problematic is that some of these extensions pretend to be security relevant. Including phishing protection or content filters.
Out of these 42 extensions 23 did not mention data collection in their terms, out of these 12 further have no URL where this would be explained. One URL that is used across 12 extensions to explain the privacy ramifications is http://addons-privacy.com. The only extension offering opt-in to tracking is "SpeakIt!". They had an issue opened here where someone pointed this out as spyware before introduction of the opt-in step.
All data is compiled into a spreadsheet, available here.
Noteworthy examples
Do it - a Shia LaBeouf motivator: In exchange for browsing history users can get motivated by Shia. The extension offers a button that will make him pop up and shout a motivational quote. 200 thousand users considered this a good deal, who am I to judge? :-)
Video AdBlock for Chrome - this extension is advertised as "ADWARE FREE We are not injecting any third-party ads!". Technically this might be correct. Is spyware and adware the same?
Taking a peek
To see what is transmitted I modified the phishing extension (and all others) to post data to my local server instead of theirs. This was fairly simple - I set up a python Flask application that accepts POST requests to /related and GET requests to /settings. The POST data is base64 encoded - twice. Why twice? I don't know. Below is the data the server-side sees while the client is browsing. Line breaks inserted to help readability.
# We go to bing, after previously visiting asdf.com:
s=714&md=21&pid=gvOq01lLa3ZBt6z&sess=475474837468937000&q=http://www.bing.com/
&prev=http://asdf.com/&link=0&sub=chrome&hreferer=&tmv=3015
# We send a query "this is a test":
s=714&md=21&pid=gvOq01lLa3ZBt6z&sess=475474837468937000&q=http://www.bing.com/search?
q=this+is+a+test&go=Submit&qs=n&form=QBLH&pq=this+is+a+test&sc=8-14&sp=-1&sk=&
cvid=456B43655F44452BB33CC9AE204294B3&prev=http://www.bing.com/&link=1&
sub=chrome&hreferer=http://www.bing.com/&tmv=3015
# We click a link on the bing results:
s=714&md=21&pid=gvOq01lLa3ZBt6z&sess=475474837468937000&q=https://en.wikipedia.org/wiki/This_Is_Not_a_Test!&
prev=http://www.bing.com/search?q=this+is+a+test&go=Submit&qs=n&form=QBLH&pq=this+is+a+test&sc=8-14
&sp=-1&sk=&cvid=456B43655F44452BB33CC9AE204294B3&link=1&sub=chrome&hreferer=http://www.bing.com/search?q=this+is+a+test
&go=Submit&qs=n&form=QBLH&pq=this+is+a+test&sc=8-14&sp=-1&sk=&cvid=456B43655F44452BB33CC9AE204294B3&tmv=3015
What data will be transmitted?
Every visited website
Search queries (Google, Bing, etc. )
Websites visited on internal networks
As far as I can tell this will not be transmitted:
POST data (e.g.: passwords, usually)
Keypresses
The network view
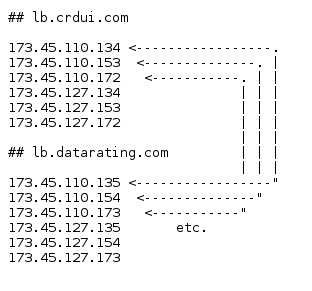
The endpoints that receive the data use a variety of domain names with multiple IPs. These 42 extension use nine distinct domains, eight of which use the same subdomain (lb.domain.com), one is a subdomain of upalytics.com. I suspect an attempt to distract from the impression that all data flows to one company. The domain names include ones that are supposed to look benign, connectupdate.com, secureweb24.net, searchelper.com. The other domains involved are: crdui.com, datarating.com, similarsites.com, thetrafficstat.net, webovernet.com.
All these domains are registered with domainsbyproxy, a service used to obscure the ownership of domain names. This includes upalytics.com itself which is used in one of the extensions (Speakit!). Also, the robots.txt file used in all cases is the same.
What's more interesting: All these IPs belong to the same hoster, XLHost.com. Eight out of nine of these hosts have all addresses in a /18 network, half of the IPs of the upalytics.com endpoint are in another xlhost network. For browsing convenience (or your firewall?) the list of IPs is available here. All IPs in use are unique, however, this involves consecutive IP addresses and other neighborhood relationships.
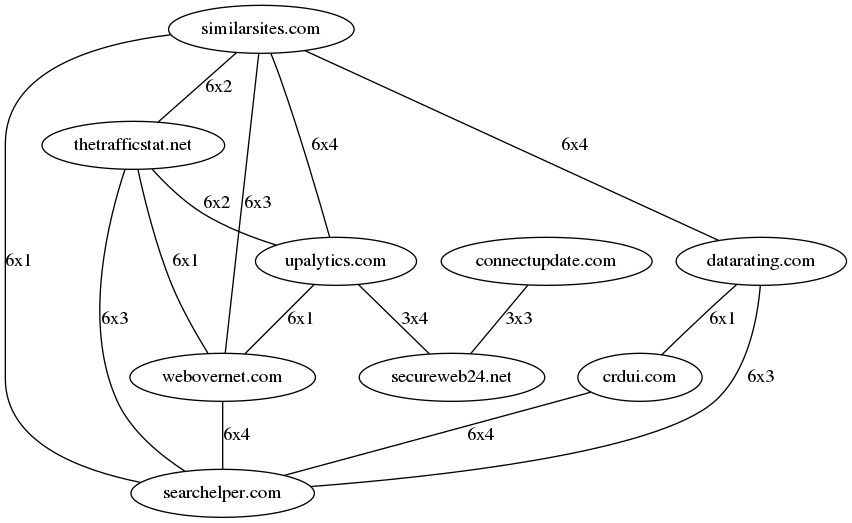
To examine this closer I compared the distance of IP addresses used by these extensions for tracking. In the graph below, the nodes are the nine domain names in use, edges are amount x distance. By taking into account distances of up to four, we can link together all hostnames used in all 42 extensions. For example: IPs "1.1.1.1" and "1.1.1.3" have a distance of 2. As for the labels, the edge between "similarsites.com" and "thetrafficstat.net" reads "6x2". This means that the domains share 6 IP addresses with a distance of 2. Before the graph, this is the relationship between lb.crdui.com and lb.datarating.com:
Combining all hosts into one graph, we get this:
What does this imply? Whether this is one large data kraken or pure coincidence, I will leave for the reader to decide.
Is this malware, an unwanted feature, or totally OK?
Some of these extensions have terms that mention privacy, here is an example:
We consider that the global measuring and ranking of the Internet in the current market is somewhat underdeveloped and obscure. For this reason, we have undertaken a large global project which bring a powerful improvement in the public’s perception of internet trends and expand the overall comprehension of the dynamics that are happening on the internet on daily basis. In order to make this goal a reality, we need anonymous data such as browsing patterns, statistics and information on how our features are being used. When installing one of our free products, you will expect to become a proud part of this project and make this change happen together with us. If you want more details on the interaction that will be going on between your browser and our servers, feel free to check out our Privacy Policy. By installing our product you adhere to the Terms and Conditions as well as Privacy Policy adhered on: http://crxmousetou.com/
Calling the data "anonymous" seems bold, an IP alone can often be used to uniquely identify users, let alone browsing history. Based on this text the majority of users might not be aware of the extent of monitoring. I was surprised myself by the boldness of the tracking. However, even if this was laid out clearly in the terms, common sense dictates that browser extensions have no business recording unrelated traffic.
That being said, this behavior could be in violation of the Extension Quality Guidelines, in particular the "single purpose" rule. Whether this is the case, I can not judge.
Limitations
This post looks into usage of this one library in the Chrome Extensions in the Chrome Web store alone. The number of extensions I found is to be considered as a lower bound, there could be well more. For the extensions I examined I did not check other libraries that were loaded or checked for behavior other than tracking browsing history. Upalytics also offers libraries for other platforms (Smartphones, Desktop, other browsers) - I did not take a look at these either.
Closing
This is just one library for one platform. Uplaytics supports all major smartphones, browsers but also Microsoft and Mac platforms. Also, there are more players in the game than this one.
I'm afraid to say that even if all these extensions get nuked from the store, there might be plenty similar libraries in other extensions.
Updates
04/01/16: None of these extensions are accessible in Google Web store at this point.
03/31/16: I expanded on the explanation of the IP relationships.
10/05/17: We published a paper to detect such leaks automatically. See here for details.
In this post I will provide some background information on the Kendall challenge of the Boston Key Party CTF. The focus is rather on how the challenge was designed than how to solve it. I'm sure others will cover that perspective in writeups.
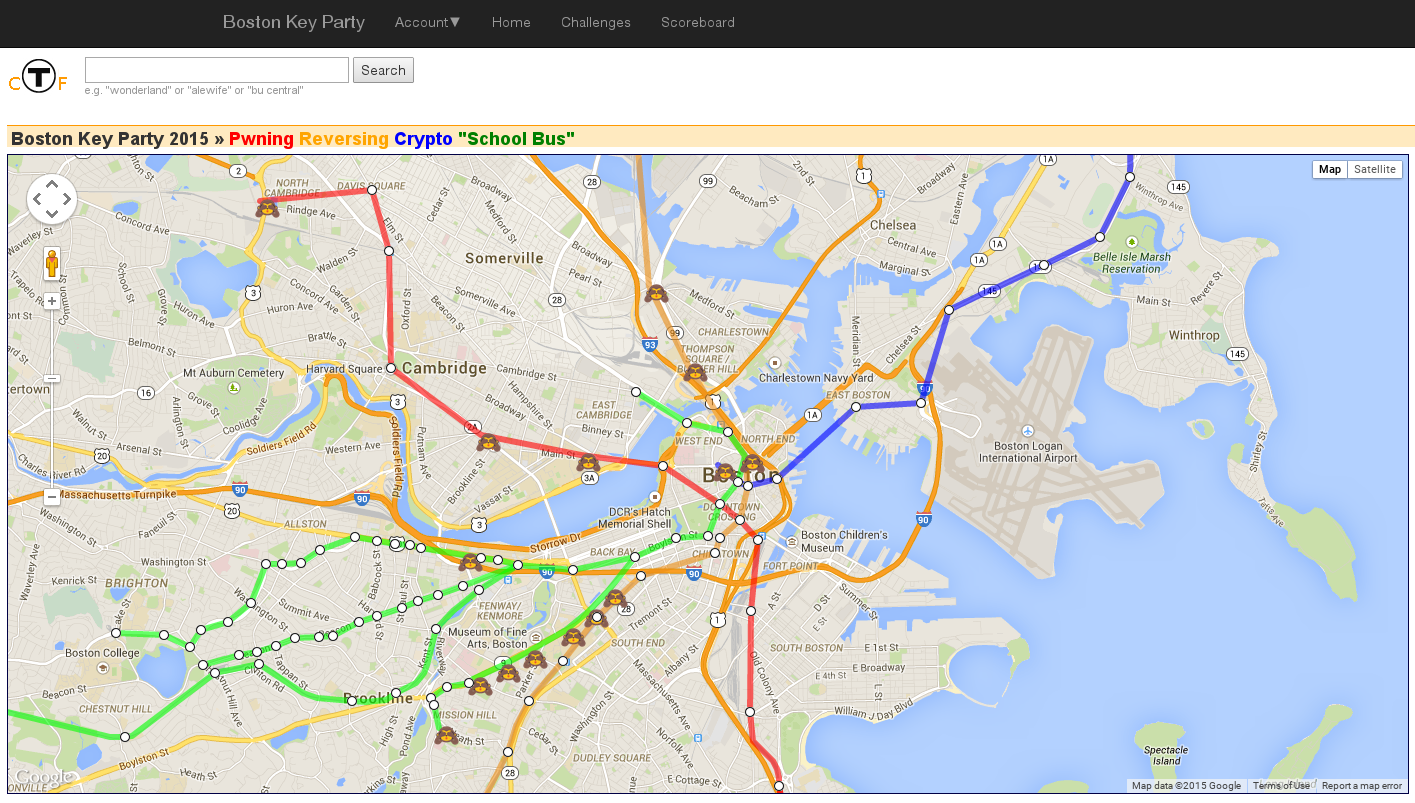
This CTF is mostly run by BUILDS, but also with some challenges from others including Northeastern SecLab. The game board was organized by MBTA stations as a Google Maps layover, courtesy of Jeff Crowell.
The challenge categories were organized by train lines. The blue line was crypto, orange was reversing, red line was pwning. Everything else ended up on the green line.
For the Kendall challenge (pwning, 300 pts) we wanted to combine multiple tasks that require different skills into a single more complicated challenge. Also, we also wanted to create something around the recent Lenovo / Superfish news stories. However, creating a challenge titled "Super*" or "*fish" would have given away too much. We had to be more sneaky about this, but also avoiding giving away too little having players try to guess what to do.
We ended up with a combination of a remote exploitable router that leads on to man-in-the-middling a SSL connection that has the superfish certificate installed. Players were provided with IP/Port of the pwnable router and the binary that was running there.
A breakdown of the steps necessary to finish:
pwn the binary
Bypass authentication
Overwrite DNS entries with DNS controlled by team
Trigger DHCP renew
Intercept Browsing
Set up DNS server that responds with team's IP
Listen to the requests and make them succeed
Interpret the HTTP request
Set up SSL interception with Superfish CA
Part 1: The Router
The router software was remote accessible. When connecting, users were greeted by the following screen:
#####################################################
# DHCP Management Console #
# Auditing Interface #
#####################################################
h show this help
a authenticate
c config menu
d dhcp lease menu
e exit
[m]#
The user can operate as guest, anything important requires to be administrator. Read: there is an easy buffer overflow in the "filter" menu option, it allows to overwrite the admin flag. We included log files which hinted at the DHCP setting being important (it reads a static file). Players had to bypass authentication and then change the DNS to point to one of their machines. Next, trigger "renew leases". What happens in the background: the program will call another program in the same directory which pushes the DNS setting to something that drives the browser via sockets. This process will directly kick off an artificial browser that issues two web requests. We separated the accounts of the binary and the browser to make finding shortcuts to the flag harder.
Note: much of the work with the router binary was done by Georg Merzdovnik.
Part 2: The Browser
We simulated a user browsing websites. First a HTTP site, later log into their bank account where some sensitive information is revlealed (the flag). Should any step in this process fail, the browser aborts operation. The "browser" was a python script using urllib2. Parts that were important to get right were the DNS queries and certificate validation. The DNS lookups had to be performed through the server the teams provide by owning the router only. The SSL request verifies against the superfish certificate only. By default urllib2 will not check authenticity of certificates.
Once teams pushed their IP address as DNS server, they could see two incoming DNS queries. One for yandex.ru and the second one for a made up hostname "my.bank"
Next, players had to reply with an IP they control and have a running web server to intercept the requests. For my local testing I used minidns, a dependency-free python script that will resolve any hostname to a single IP address.
One thing I dislike while solving challenges is pointless guessing. So, before making a HTTPS request we issued a HTTP request to give a hint what to do with the SSL connection. We added a new header, namely "X-Manufacturer" with the value "Lenovo". This is a completely made up header which was supposed to be a hint towards Superfish without being blatantly obvious.
The second request was pointed at "https://my.bank" Teams had to make the browser establish a legitimate SSL connection and we would issue a request to: "https://my.bank/login/username={0}".format(self.FLAG)
Although we had no specific format for keys, we decided to prefix the key with "FLG-" to make it obvious once players got that far.
To get this right, teams could either run a web server with the Superfish private key, or MITM and point the request somewhere else.
A writeup using sslsplit for the latter option is available on Rob Graham's blog.
Closing
The source code of the challenges will be released as a tarball at some point in the near future, follow @BKPCTF (or me) for updates. I hope the challenge was fun and am looking forward to hear in writeups how teams did it.
In December 2012, I was curious who is using Content Security Policy, and how are they using it?
Content Security Policy (CSP) can help websites to get rid of most forms of content injection attacks. As it is standardized and supported by major browsers, we expected websites to implement it. To us, the benefits of CSP seemed obvious.
However, as we started to look into the CSP headers of websites, we noticed that few of them actually used it. To get a better overview we started crawling the Alexa Top 1M every week. What started out as a just-for-fun project escalated to a data collection of over 100GB of HTTP header information alone. We are publishing the results in our (Michael Weissbacher, Tobias Lauinger, William Robertson) paper Why is CSP Failing? Trends and Challenges in CSP Adoption at RAID 2014.
We investigated three aspects of CSP and its adoption. First, we looked into who is using CSP and how it is deployed. Second, we used report-only mode to devise rules for some of our websites. We tried to verify whether this is a viable approach. And third, we looked into generating content security policies for third-party websites through crawling, to find obstacles that prevent wider deployment.
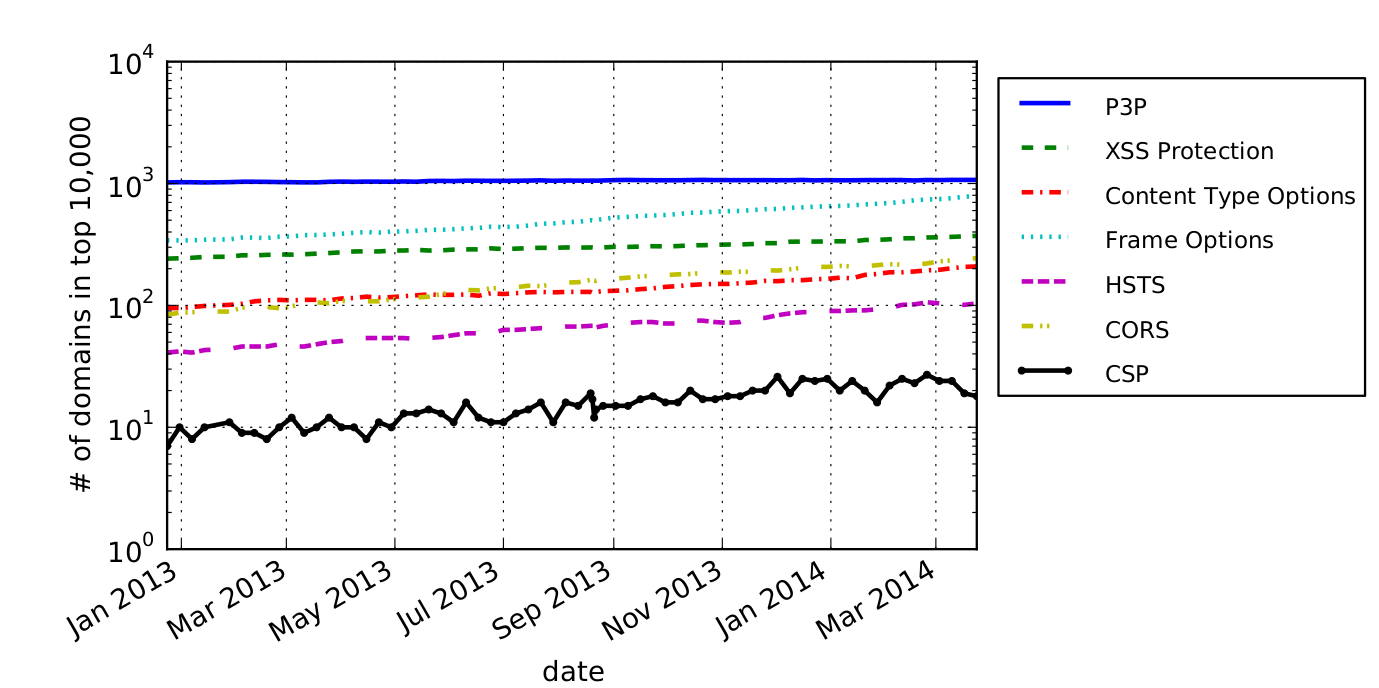
CSP headers in comparison to other security relevant headers
We have found that CSP adoption significantly lags behind other web security mechanisms and that, even when it has been adopted by a site, it is often deployed in a way that negates its theoretical benefits for preventing content injection and data exfiltration attacks. While more popular websites are more likely to use it, only 1% of the 100 most popular websites use it on their front page.
To summarize our findings:
Out of the few websites using CSP, the policies in use did not add much protection, marginalizing the possible benefits.
The structure of sites, and in particular integration of ad networks, can make deployment of CSP harder.
CSP can cause unexpected behavior with Chrome extensions, as we detail below.
The project resulted in fixes to phpMyAdmin, Facebook and the GitHub blog.
In our paper, we suggest several avenues for enhancing CSP to ease its adoption. We also release an open source CSP parsing and manipulation library.
Below, we detail on some topics that did not fit into the paper, including bugs that we reported to impacted vendors.
Chrome Extensions
Chrome enforces CSP sent by websites on its extensions. This seems well known, but comes with a couple of side effects. The implications are that CSP from websites can break functionality of extensions, intentionally or unintentionally. Other than that, it makes devising CSP rules based on report-only mode very cumbersome, due to lots of bogus reports. Enforcing rules on extensions seems surprising, especially since they can request permission to modify HTTP headers and whitelist themselves. In fact, we found one such extension that modifies CSP headers in flight.
Recovering granularity of CSP reports
While older versions of Firefox will report specifically whether an eval or inline violation occurred, newer versions of any browser won’t. We provide a work-around to detect such errors in the paper, this involves sending multiple headers and post-processing the reports.
Facebook
With Facebook, we noticed that headers (including CSP) were generated based on the user agent. This has some advantages, e.g., sending less header data to browsers that don’t support certain features. Also, Firefox and Chrome were sent different CSP headers (the difference being, the Skype extension was whitelisted for Chrome.) We also noticed that for some browser versions, no CSP rules were sent out. The likely reason is that CSP handling in some browser versions is buggy. For example, Chrome enforces eval() even in report-only mode in some versions. However, due to misconfiguration, CSP was only served to browser versions before the bugs were introduced, and none after. As a result, CSP was only in use for a fraction of browsers that in fact support it. After we informed them of this, Facebook quickly fixed the issue. Now, CSP is being served to a wider audience of browsers than before. Also, we were added to the Whitehat “Thanks” list.
phpMyAdmin
We found that phpMyAdmin, which serves CSP rules by default, had a broken configuration on it’s demo page. The setup prevented loading of Google Analytics code. This turned out to be interesting, as the script was whitelisted in the default-src directive, but script-src was also specified and less permissive. Those two are not considered together, and the more specific script-src directive overrode default-src. Hence, including the Google analytics code was not allowed and resulted in an error. We pointed out the issue and it resulted in a little commit.
GitHub
We used several sites that deploy CSP as benchmark to test our tool for devising CSP rules. With GitHub, we noticed that our tool came up with more directives than the site itself. After investigating, we found that one of the sites on their blog was causing violations with the original rules, as it tried to include third party images. This was interesting, as any site which specifies a report-uri would have caught this, but GitHub doesn’t use the feature. While this caused no security issue, it stopped the blog post from working as intended. With report-uri enabled that mistake would have popped up in the logs and could have been fixed instantly. We think this highlights how important usage of the report-uri is. In summary, this was more of an interesting observation about report-uri to us than a problem on their side.
The 2012 Qualification round for CSAW CTF was fun. I was playing with the Northeastern Seclab hacking group - PTHC. One of the more interesting challenges was networking 300.
As input we received a file called "dongle.pcap", no further description.
The first thing to do with pcaps is to load them in wireshark. The type for most packets is URB_Interrupt or URB_Control (URB is a USB request block). Most of the packets don't look interesting - by browsing we found packet 67 which contains the following string: "Teensy Keyboard/Mouse/Joystick", this made us assume that we have to deal with recovering key presses.
Some quick googling lead us to this website, we downloaded the source files and inspected the code to analyze the protocol. We figured out that the packets we are interested in are pretty specific, they should be:
- 72 bytes long
- the 10th byte is \x01
- the 12th one is \x1a
- the 66th byte should be non-zero
- also we only care about the last 8 bytes and can disregard the rest
import binascii
from scapy.all import *
dongle = rdpcap("dongle.pcap")
for d in dongle:
sd = str(d)
if len(sd) == 0x48 and sd[9] == '\x01' and sd[11] == '\x1a':
x = sd[len(sd) -8:]
print binascii.hexlify(x)
This leaves us with 1338 packets, the last four bytes are all \x00. We inspect the file usb_keyboard_debug.h from the keyboard's source file and can see the key mapping. "A" = 4 etc. We created a mapping keycode-output and prepended it to our script so we would see the keyboards behavior. By inspecting the pcap we found that there were no ALT or STRG key presses, only shift and only for a couple of keys (3). For the sake of simplicity we decided just to check for these three cases in additional if clauses without making a generalized upper-case function. What we get from running the updated program:
The string "KEY{...}" made us assume we finished, but the scoreboard disagreed. It took us a while to figure out that we also have to take the RXTERM lines into account - the last two numbers (separated by "+" are the coordinates). That was the last part of the puzzle and we got the points.
The following program is the cleaned up, final version that will parse the pcap file, pull out the key presses, write the keys into a matrix with the corresponding coordinates and print them in order.
from scapy.all import *
import binascii
keys = {}
keys[4]='A'
keys[5]='B'
keys[6]='C'
keys[7]='D'
keys[8]='E'
keys[9]='F'
keys[10]='G'
keys[11]='H'
keys[12]='I'
keys[13]='J'
keys[14]='K'
keys[15]='L'
keys[16]='M'
keys[17]='N'
keys[18]='O'
keys[19]='P'
keys[20]='Q'
keys[21]='R'
keys[22]='S'
keys[23]='T'
keys[24]='U'
keys[25]='V'
keys[26]='W'
keys[27]='X'
keys[28]='Y'
keys[29]='Z'
keys[30]='1'
keys[31]='2'
keys[32]='3'
keys[33]='4'
keys[34]='5'
keys[35]='6'
keys[36]='7'
keys[37]='8'
keys[38]='9'
keys[39]='0'
keys[41]='ESC'
keys[43]='TAB'
keys[45]='-'
keys[46]='EQUAL'
keys[47]='LEFT_BRACE'
keys[48]='RIGHT_BRACE'
keys[49]='BACKSLASH'
keys[50]='NUMBER'
keys[51]='SEMICOLON'
keys[52]='QUOTE'
keys[53]='TILDE'
keys[54]='COMMA'
keys[55]='PERIOD'
keys[56]='SLASH'
keys[57]='CAPS_LOCK'
keys[58]='F1'
keys[59]='F2'
keys[60]='F3'
keys[61]='F4'
keys[62]='F5'
keys[63]='F6'
keys[64]='F7'
keys[65]='F8'
keys[66]='F9'
keys[67]='F10'
keys[68]='F11'
keys[69]='F12'
keys[72]='PAUSE'
keys[74]='HOME'
keys[75]='PAGE_UP'
keys[76]='DELETE'
keys[77]='END'
keys[79]='RIGHT'
keys[80]='LEFT'
keys[81]='DOWN'
keys[82]='UP'
keys[83]='NUM_LOCK'
keys[89]='KEYPAD_1'
keys[90]='KEYPAD_2'
keys[44]=' '
keys[40]='ENTER'
dongle = rdpcap("dongle.pcap")
buf = {}
buf[1] = ""
for d in dongle:
sd = str(d)
if len(sd) == 0x48 and sd[9] == '\x01' and sd[11] == '\x1a' and sd[0x42] != '\x00':
x = sd[len(sd) -8:]
# only these three keys get used with shift
if x[0] == '\x02':
if keys[ord(x[2])] == "EQUAL":
key = "+"
elif keys[ord(x[2])] == "RIGHT_BRACE":
key = "}"
elif keys[ord(x[2])] == "LEFT_BRACE":
key = "{"
else:
key = keys[ord(x[2])]
if key == "ENTER":
print buf[len(buf)]
buf[len(buf)+1]=""
key = "\n"
else:
buf[len(buf)] += key
# putting keys on their corresponding coordinates
matrix = {}
for i in range(1,len(buf),2):
(a,b,c) = (buf[i]).split("+")
if int(c) not in matrix.keys():
matrix[int(c)] = {}
# look ahead for one line - the echo command
matrix[int(c)][int(b)] = buf[i+1][-1:]
# print pressed keys in order
for x in sorted(matrix.keys()):
for y in sorted(matrix[x].keys()):
print "{a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6}03d-{a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6}03d-{a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6}s" {a1e0ea66cab8e2163484f308b55c8b73124cdcf3d3411fefce873f0243ccaee6} (x,y,matrix[x][y])
This weekend PPP organized its second PlaidCTF which was a lot of fun. Below is a quick writeup for the bittorrent forensics challenge.
Description:
It turns out that robots, like humans, are cheap and do not like paying for their movies and music. We were able to intercept some torrent downloads but are unsure what the file being downloaded was. Can you figure it out?
Provided was a file torrent.pcap, we used tshark (the command line tool for wireshark) to extract data from the packet capture. The only interesting data points are bittorrent.piece, from those we only need index, begin and data. By printing them in this order we can run a simple sort to make sure the file contents are in order.
Next we strip everything but the data field and the colons. Finally we use translate and sed to turn the hex representation into binary. After running the below script we have a file binout.
By using the file command and consequently unpacking we figure out its a bz2-ed tar file. Inside we find the files key.mp3 and key.txt. key.txt contains "t0renz0_v0n_m4tt3rh0rn", which turned out to be the valid key. We couldn't extract any hidden information from key.mp3 :-)
Note: if you are trying to reconstruct a file from a bittorrent pcap you might want to check for retransmits, missing indices, multiple files in one capture etc. It would make sense not to strip the headers directly with sed but keep them and run some script to analyze them.
One of my iCTF challenges was a simple JavaScript obfuscation, a backup of the code is available here. What happens is obvious, window.alert is triggered with the message “why?”. “Why” is less obvious since the code was encoded with jjencode. There are no other visible hints.
To further look into window.alert, we can overwrite the function:
FYI: Before the obfuscation the code looked like this:
varobj={};obj.secret="Angelina Jolie's only good movie, in leet speak, reverse is the key";obj.toString=function(e){return"why?";};obj.toSource=function(e){return"function toSource() {\n"+" [native code]\n"+"}\n"};window.alert(obj);
This is a writeup of the PlaidCTF 500 pts challenge “Fun with Firewire”.
Description:
Category: forensics
All of the machines at the AED office are encrypted using the amazing TrueCrypt software.
When we grabbed one of their USB sticks from a computer, we also grabbed the memory using the Firewire port.
Recover the key using the truecrypt image and the memory dump.
http://www.plaidctf.com/chals/81d9467f812d2fbb32e9d4b915cccfe457245f25.tar.bz2
Introduction
Given is a memory dump (128 MB) of a running Windows XP SP3 machine as well as a 32 MB file containing random data (a TrueCrypt volume image, according to the problem description). The memory dump was supposedly extracted via the Firewire port: The Firewire specification allows devices to have full DMA access. This allows forensic analysts (or a malicious hacker) to plug into any running computer that has a Firewire port and gain full access to the machine within seconds. Papers describing the attack and tools can be found at http://www.hermann-uwe.de/blog/physical-memory-attacks-via-firewire-dma-part-1-overview-and-mitigation. A different way to get a dump of the memory would be to conduct a “cold boot attack” as described in this paper.
Overview
To get an overview of the memory dump we inspect it with volatility. We see that TrueCrypt was running at the moment the dump was taken … good.
Further inspection of the memory dump reveals that the Operating System is Windows XP SP3, and the latest version of TrueCrypt (7.0a) is used. We reconstruct the setup by launching a VirtualBox installation, and we extract the memory using Mantech Memory Dumper mdd http://sourceforge.net/projects/mdd/. TrueCrypt offers the possibility to cache the passwords for mounting encrypted volumes. Comparing different memory dumps let us conclude that password caching was not enabled in the TrueCrypt software.
We briefly summarize the relevant technical details of TrueCrypt. More information can be found at http://www.truecrypt.org/docs/. In order to mount an encrypted volume, TrueCrypt uses the password and/or one or more key-files in order to decrypt the header (first 512 bytes of the volume). If the header gets correctly decrypted (a magic cookie is found), TrueCrypt reads the configuration (encryption algorithm and mode, etc.) as well as the master and secondary key into memory, and safely overwrites the memory regions where the password / key-file location was stored. The extracted master and secondary key is used for any further encryption and decryption of data. Since the data is encrypted and decrypted on the fly, these keys remain in memory. (Note that recent papers suggest storing the keys in CPU registers, more specifically in SSE registers http://portal.acm.org/citation.cfm?id=1752053 or in MSR registers http://arxiv.org/abs/1104.4843 instead of in the RAM in order to mitigate against these attacks.).
The default cipher used by TrueCrypt is AES in XTS mode which uses two 256 Bit AES-keys. We have to locate these keys in the memory dump. One option would be to analyze the data-structures and locate the memory region where TrueCrypt stores the keys.
But it is easier to use a generic approach to locate AES keys since a tool for that task was already written for the “cold boot attack” research: AESKeyFinder.
Once we have the right keys, we replace the header of the encrypted volume with the header of an identical volume which we created and where we set the password (so that TrueCrypt starts the mounting process correctly), but have TrueCrypt patched so that it uses the extracted keys from the memory dump instead of the ones from the newly generated header.
Finding the keys
AESKeyFinder inspects memory dumps (or actually any kind of files) and performs a simple heuristic to estimate entropy. The tool targets the expanded AES keys and tests whether a contiguous region in memory satisfies the constraints of a valid AES key schedule https://secure.wikimedia.org/wikipedia/en/wiki/Rijndael_key_schedule.
The “constraint on rows”-output tells us that the expanded keys are valid according to the AES key schedule. If we had bit errors in the respective memory regions (likely in cold boot attacks), not all constraints would have been met and AESKeyFinder would have calculated a guess for the original valid key.
So we have three keys after only a few of seconds of runtime - so far so good.
The entropy of (3) is really low, and we can definitely exclude it if we assume TrueCrypt is not totaly broken. This is good news since we have exactly two remaining 256-bit AES keys, as used by TrueCrypt in default configuration (AES in XTR mode).
Patching TrueCrypt
Next we read the source of TrueCrypt. Remember that TrueCrypt first decrypts the header with the password, and then reads the AES-key from the decrypted header. Reading in the header is done in Volume/VolumeHeader.cpp:VolumeHeader::Deserialize(.,.,.). We patch the code there, right after the master and secondary key was read from the decrypted header, and replace it with the hard-coded key value we found in the previous step. Our quick and dirty patch looks as follows:
In order for TrueCrypt to reach the patched code it must first correctly decrypt a valid header. So we copy the header from an identically sized TrueCrypt volume configured with the default parameters:
and open ppp.challenge.vol with the patched TrueCrypt software and find the file KEY.TXT in the correctly decrypted volume.
Summary
This was a really nice challenge letting us explore TrueCrypt internals. If you think this is too complicated - you are right. You can also solve the challenge with available tools.
People involved in solving this challenge: Clemens Hlauschek, Michael Weissbacher